
How to evaluate your RAG Pipeline
A Step-by-Step to evaluate your RAG Pipeline RAG Pipeline’s evaluation works as checking and ranking the performance and setup of every document and all the data used in the Pipeline. There are two steps where a satisfactory LLM output can be compromised, Retrieval and Generator.
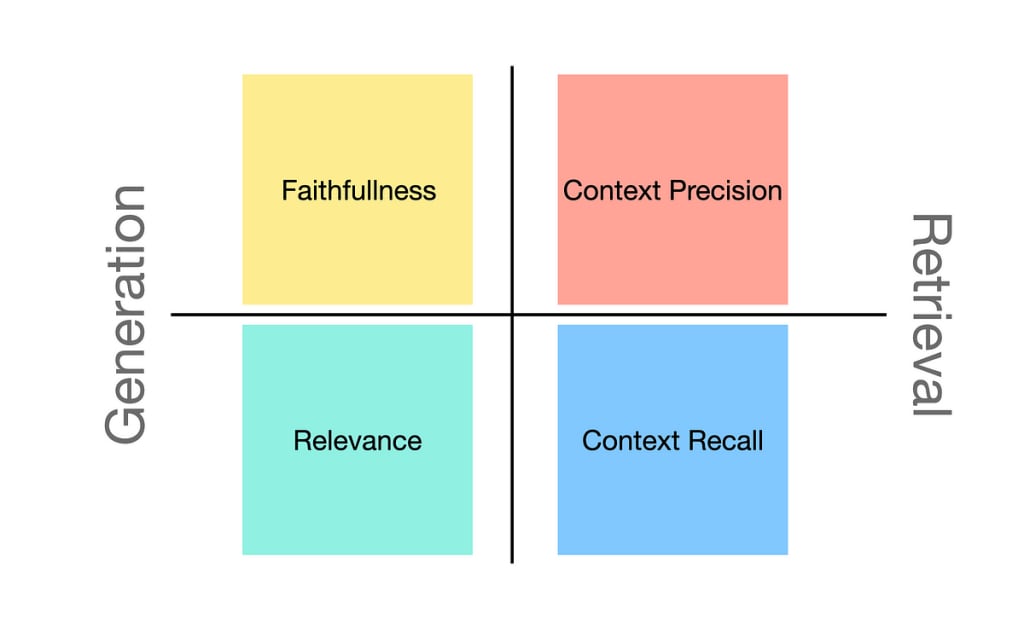
RAG Pipeline’s evaluation works as checking and ranking the performance and setup of every document and all the data used in the Pipeline. There are two steps where a satisfactory LLM output can be compromised, Retrieval and Generator.
Running these evaluations are very useful when you’re building your first RAG Pipeline version; but the benefit of running these evaluations continue post-development.
Running these evals in production will help you understand your system's current performance relative to the potential improvements you could achieve by modifying your prompts.
Building the concept of a RAG Pipeline is easy but getting the RAG’s performance up to the mark is another level of difficulty in comparison.
What is RAG Pipeline:
The Retrieval-Augmented Generation (RAG) pipeline is a framework in natural language processing that combines the strengths of retrieval-based and generation-based models. It first retrieves relevant documents or passages from a large corpus using a retriever model, then uses a generator model to produce a coherent and informative response based on the retrieved information. This approach enhances the quality and accuracy of generated text, making it particularly useful for tasks requiring specific and contextually rich information.
What is RAG Pipeline Evaluation:
RAG Pipeline Evaluation assesses the performance of the RAG framework. It involves measuring how well the retrieval and generation components work together to produce accurate, relevant, and contextually appropriate responses.
Key evaluation metrics include retrieval accuracy, response relevance, coherence, and informativeness. This evaluation ensures the pipeline's effectiveness in applications like question answering and conversational AI, guiding improvements in model training and optimization.
There are two components of a RAG Pipeline that can be evaluated: Retrieval and Generation Components.
Retrieval Component:
The aims of evaluating the retrieval component are to check if:
Is the embedding model compatible and relevant to the desired output
Does the reranker model ranks the retrieved nodes correctly
The amount and size of information is correct or not
Checkmarking these aims complete involve checking these variables like embedding model, retrieved nodes, reranker model, which are known as hyperparameters also shown as top-K here onwards.
There are different tools which can be used along to evaluate in a more efficient way like deepeval, LlamaIndex, and RAGA.
Using deepeval:
To evaluate retrieval, deepeval offers three LLM evaluation metrics:
Contextual Precision Metric
Contextual Recall Metric
Contextual Relevancy Metric
Precision Metric involves evaluates whether the reranker is up to the mark or not and ranks more relevant nodes compared to the irrelevant ones.
Recall Metric involves checking if the embedding model in the retriever is capturing and retrieving relevant information accurately or not.
Relevancy Metric consists of evaluating if the text chunk size and top-K are able to retrieve correct information but mostly relevant information
These three metrics are needed as a combination in the right amount so that you know that the retriever is retrieving and sending the right amount of information to the generator.
A simple way of evaluating retriever is to use “test_case” with each metric as a standalone.
Using Llama Index:
To evaluate via Llama Index using an evaluation dataset which has to be made before starting the evaluation.
First create the Retriever and then define two functions: get_eval_results, which operates retriever on the dataset, and display_results, which presents the outcomes of the evaluation. You can use Hit Rate and MRR metrics to evaluate the retriever.
Hit Rate:
It calculates the part of queries where the correct answer is found within the top-k retrieved documents. In simpler terms how much queries were correct out of the total queries.
Mean Reciprocal Rank (MRR):
MRR is slightly different than Hit Rate in terms of how it calculates accuracy but they both calculate accuracy.
MRR evaluates the system’s accuracy by looking at the rank of the highest-placed relevant document. Specifically, it’s the average of the reciprocals of these ranks across all the queries.
Generative Component:
The aims of evaluating the Generative component are to find out:
Can a smaller, cheaper and faster LLM be used?
Relationship between prompt template affect output quality
Would a higher temperature improve results?
Using deepeval:
These two are the key metrics that deepeval uses to evaluate RAG Pipelines:
Answer Relevancy Metric
Faithfulness Metric
Just like retrieval component, these two metrics should be showing results in tandem with each other.
Using Llama Index:
Llama Index uses these two metrics for evaluation of Generative component:
Faithufulness Evaluator
Relevancy Evaluator
Faithfulness Evaluator checks if the given output has any relation with the source nodes and if so are they credible enough
Relevancy Evaluator evaluates if the given output and the source nodes have any relation with the given input, to check if they even answer the user’s question or its useless.
Evaluation with RAGAs:
RAGAs stands for Retrieval-Augmented Generation Assessment is another framework used for evaluation of RAG Pipeline. It is slightly different than the others as instead of having to rely on human-annotated ground truth labels, RAGAs use LLMs to conduct these evaluations.
This makes RAGAs a cheaper and faster evaluation method but since its new and not used much there might be some shortcomings lying under there.
These are some of the key metrics used in RAGAs:
Context Relevancy
Context Recall
Faithfulness
Answer Relevancy
Conclusion:
Evaluating your RAG pipeline is a crucial step in unlocking its full potential. By taking a closer look at both the retrieval and generative components, you can pinpoint areas for improvement and fine-tune your system for peak performance. With the help of powerful tools like deepeval, LlamaIndex, and RAGAs, you can tap into a wealth of metrics - from Contextual Precision to Answer Relevancy - to guide your optimization journey.
Regular check-ins during development and production ensure your RAG system stays on track, adapting to changing requirements and delivering reliable results.
About the Creator
Enjoyed the story? Support the Creator.
Subscribe for free to receive all their stories in your feed. You could also pledge your support or give them a one-off tip, letting them know you appreciate their work.
Keep reading
More stories from Vectorize io and writers in Education and other communities.
5 tips you need to follow to make a better RAG Pipeline
RAG Pipelines are at the forefront of a transformation in the landscape of Artificial Intelligence’s technology. Systems for RAG Pipelines are designed to improve and personalize the replies they produce. These systems function in two stages: first, they obtain relevant data from a knowledge base, and then they utilize that data to provide a response.
By Vectorize io16 days ago in Education
HEALTHFUL LIFE
Living a healthy life is a multifaceted endeavor that encompasses many different aspects of our daily routines, behaviors and choices. It is not merely the absence of disease but a state of complete physical, mental and social well-being. Achieving and maintaining a healthy lifestyle requires a balanced approach that includes proper nutrition, regular physical activity, adequate sleep, stress management, and preventive health care measures.
By shumaila bibiabout 15 hours ago in Education




Comments (1)
Glad you shared this.