
5 tips you need to follow to make a better RAG Pipeline
5 tips you need to follow to make a better RAG Pipeline
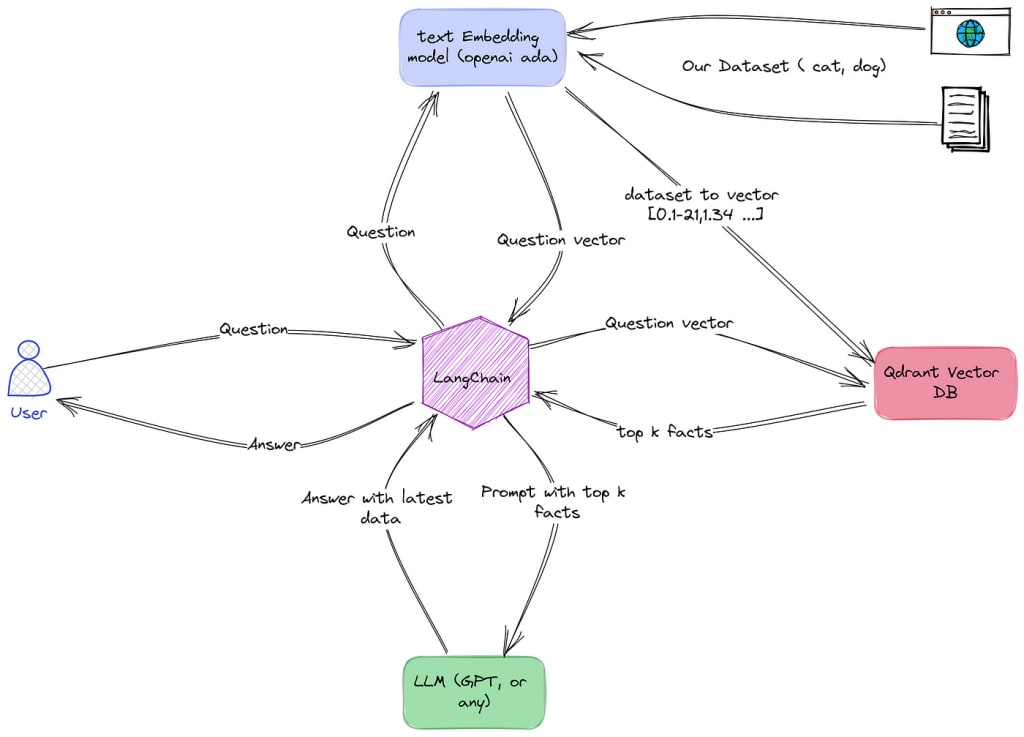
RAG Pipelines are at the forefront of a transformation in the landscape of Artificial Intelligence’s technology.
Systems for RAG Pipelines are designed to improve and personalize the replies they produce. These systems function in two stages: first, they obtain relevant data from a knowledge base, and then they utilize that data to provide a response.
By doing this, the system guarantees that the answer is grounded on actual knowledge, improving its accuracy and dependability. Retrieval augmented generation systems have demonstrated encouraging outcomes in question answering, conversation system creation, and information summarization in recent years. Retrieval-augmented generation's fundamental idea is to use outside information to improve the generated content's relevance, coherence, and fluency.
Expansion of Queries
By adding more words or synonyms to the original query, query expansion techniques seek to improve the relevancy of the information that is obtained. This makes it easier to get a larger collection of pertinent files or data. Retrieval accuracy can also be increased by rephrasing the query in light of user input or contextual data.
Knowledge Graph Extension
Integrating knowledge graphs, which capture structured information and relationships between entities, can enhance retrieval-augmented generation. By leveraging the knowledge graph, retrieval models can retrieve semantically and contextually related information, leading to more accurate and meaningful generated content.
Meta Data Filtering
To enhance retrieval, adding meta-data like dates to chunks is effective. This allows filtering by recency, crucial for relevance. For example, in an app querying email history, recent emails are likely more relevant, though not always the most similar in embeddings. This highlights a key RAG principle: similarity ≠ relevance. By appending dates to email meta-data, you can prioritize recent context during retrieval. LlamaIndex offers a class of Node Post-Processors that aids in this process.
Optimizing Chunk Size
Chunking context data is critical in the development of RAG systems. While frameworks abstract chunking, it is critical to address chunk size, as it influences retrieval and generation. Smaller chunks frequently increase retrieval, but they may lack context, which affects generation. Do not approach chunking blindly. Pinecone provides exploratory techniques. I evaluated several chunk sizes (small, medium, and large) with a series of questions and discovered that little portions were the most successful.
Selective Attention Mechanisms
Selective attention mechanisms significantly reduce the computational complexity in transformer architectures. By focusing only on the most relevant parts of the input, models can improve efficiency without compromising performance. Techniques for achieving selective attention include local attention, axial attention, and kernelized attention.
These methods ensure that the model attends to essential information, enhancing both speed and accuracy in processing large datasets. Implementing these techniques can lead to more efficient and effective transformer models.
Transfer Learning in Image Recognition
Pre-training and transfer learning are highly effective techniques in image recognition. Pre-trained models, such as ResNet (Residual Networks) and EfficientNet, have achieved remarkable success in various computer vision tasks. These models are trained on extensive datasets, learning intricate visual representations that capture rich semantic details.
By fine-tuning these pre-trained models on specific image recognition tasks, we can adapt them to particular objectives, resulting in enhanced performance. Transfer learning techniques allow the application of knowledge gained from one task or domain to another, effectively utilizing the capabilities of pre-trained models.
Incorporating pre-training and transfer learning in image recognition systems leads to better contextual understanding, more precise identification, and more accurate classification.
Conclusion:
Building a better retrieval-augmented generation (RAG) pipeline requires careful consideration of several key factors. Chunking context data effectively is crucial, as smaller chunks can improve retrieval but may affect generation quality. Efficient retrieval can be enhanced by adding meta-data like dates to prioritize recent context. Sparse attention mechanisms, which reduce computational complexity by focusing on relevant parts of the input, can boost model efficiency. Pre-training and transfer learning play vital roles in enhancing the performance of RAG systems by leveraging models trained on large datasets and fine-tuning them for specific tasks.
By incorporating these tips, researchers and practitioners can unlock the full potential of RAG systems, creating high-quality, contextually relevant, and engaging content for a wide range of applications. Continuously advancing and refining these techniques will further enhance the capabilities and effectiveness of retrieval-augmented generation.
About the Creator
Enjoyed the story? Support the Creator.
Subscribe for free to receive all their stories in your feed. You could also pledge your support or give them a one-off tip, letting them know you appreciate their work.
Keep reading
More stories from Vectorize io and writers in Education and other communities.
How are Pinecone and Chroma different
In today's data-driven world, the need for efficient and scalable ways to manage and query large datasets is more critical than ever. Vector databases have become quite significant in artificial intelligence, serving as the backbone for efficient data storage and management in neural network applications.
By Vectorize io13 days ago in Education
Tips and Tricks for Recording and Distributing a Cover Song
Recording and distributing a cover song can be a rewarding experience for any musician. It allows you to showcase your talent and pay tribute to songs you love. However, the process involves several critical steps to ensure your cover stands out and reaches the right audience. This guide offers practical tips and tricks to help you record and distribute your cover song successfully, from selecting the right song and recording high-quality audio to navigating legal requirements and promoting your work.
By Music Industry Updates2 days ago in Education
Cooperative Learning: A Path to Academic and Social Success
Cooperative learning is an instructional approach where students work together in small groups to achieve a common goal. This method is not only effective for enhancing academic performance but also for developing social and interpersonal skills. At Ecole Globale Schools, we believe in the power of cooperative learning to transform the educational experience. This article delves into the principles, benefits, and strategies of cooperative learning, providing valuable insights for parents and students.
By Priyangini 2 days ago in Education




Comments
There are no comments for this story
Be the first to respond and start the conversation.