
What is Artificial Intelligence and AI Technology Work?
What is Artificial Intelligence? How Does AI Technology Work?


We have come a long way from the time when we were all able to access only data through the use of tables and rows of paper spreadsheets to create simple algorithms which would run through the large amounts of information available on the web and find patterns in the data. The ability to program computers for decision-making and reasoning has greatly improved over the last 50 years, but this ability is limited by the existence of a few key concepts such as; data, models, prediction, learning, testing, feedback, problem-solving, and creativity. In order to successfully apply machine learning to your business, you need one or more of these concepts and their applications. As many businesses struggle with implementing Machine Learning strategies, there is still some confusion about how AI works. There are many reasons why it's important to be clear on what types of problems can benefit from using AI, but below Artificial Intelligence we'll discuss each specific aspect in detail. Read Also...
Data
The first step to getting started with AI is understanding the definition of "data" in its most basic sense. This definition covers both structured (examples and features) as well as unstructured (text, video, audio, images, etc.). At its core, you want to know whether an image, audio file, document, website, or anything else you encounter is valuable to us or not. When you Artificial Intelligence search Google Images, Google Photos, or even Google Trends, you are searching Google for data that is unique specifically to your content or topic. To further understand the difference between data that is valuable for someone who searches the words “dog” or “jaguar” (examples) versus data that is not (text), I would recommend reading these articles:
Can a Computer Learn Everything About You?
8 Things Every Entrepreneur Should Know About Customer Value.
6 Reasons Why Your Business Is Not Making Enough Money.
5 Ways to Make More Money From Each $100 Invested.
5 Major Challenges Facing Organizations Trying to Use Big Data Analytics.
10 Common Mistakes That Are Causing Startups to Fail.
A Beginner’s Guide To Using Deep Learning With Python.
What is a Convolutional Neural Network — The Simple Explanation!
Implementing Recurrent Networks For Chatbots — An Example Of Actionable Results.
Implementing RNNs On Mobile Apps Using Tensorflow.
10 Major Insights About Employee Engagement — And Their Impact On Future Growth.
Understanding Reinforcement Learning Algorithms & Examples.
Building Recommendations System For Retailers.
Exploring Which Type Of Voice Search Platform(s) Will Be Most Valuable To Buy In 2018.
15 Tips To Find Successful Jobs While Working Remotely.
Why Chatbots Are Still So Popular Today.
The goal is to make your data useful enough to justify the investment in artificial intelligence, so you don’t just collect data for different uses but also to improve existing solutions and to generate new ideas from data sets. By gathering relevant data the answer becomes easier to answer questions, develop new strategies and products, reduce costs, increase customer satisfaction and improve overall productivity. It’s no longer enough to simply provide answers to your customers you must provide insights as to why they want something from your brand. If you don’t get those answers you will lose out on potential customers who may not have been able to access them previously if you didn’t make them aware of your brand.
Models
The next step after data collection is machine learning to help you predict outcomes. It’s common to hear the phrase “machine learnings” used throughout the industry these days and it is very important to be clear on which type of model you are trying to build. There are three main kinds of predictive models: Classification Models, Regression Models, and Time Series Models.
Classification
Classification models categorically identify things such as movies, dogs, cats, and so on. They typically produce results that are based on what it means to be similar or different. However, classification is limited to discrete values, which makes it difficult for a model that predicts on continuous data. Some common examples of classification models include Linear Discriminant Analysis (LDA), Support Vector Machines (SVM), and Nearest Neighbours Classifier (NAC). These are often used in various situations where many discrete classes have to be identified at once and the output should be easy to understand because this is a binary classification. Many companies like Verizon, Yahoo and Netflix use Classification Modelling to classify users into categories such as, movie users, car users, dog owners, animal lovers, game users, news users, and others.
Regression
Regression models assume that data is continuous, rather than having a category (something it is not). Therefore regression models are built in such a way that the output from the model should make sense. One form of regression is Support Vector Regression (SVR) where we predict some real value that depends on the inputs, which is called as Support Vector Regression (SVR). SVR is often useful when you do not know what values your model should accept as parameters, or when the input to your model is measured in millions rather than being a set number. Another big advantage of a regression model is that these values do not change much throughout the year, so they are good at telling you which items are on certain items of the season, for example Christmas week and New Year’s week. Although it’s best known as being applied to regression problems, the idea behind regression is actually great for prediction problems.
Time Series
Time series analysis is a method in data science that focuses on finding correlations at time intervals, which is one of the many areas where time-series modelling is widely used. Like a classification model this process looks at grouping certain events together and then predicting future events such as stock market crash, interest rates, etc. This is a fantastic way for marketers to determine things that are likely to happen and respond to that. Just like a classification model, time series modelling is also very powerful, but there is a downside to this model. Because time series data is usually non-stationary, there aren’t any guarantees that future observations will give you the same result. Furthermore, because these observations will normally occur in cycles or long patterns a lot of the time, time series data is less informative. In general people tend to better remember things that repeat themselves. People can learn from past experiences, learn from other people’s opinions, and continue to remember situations that they saw already.
One of the advantages of these three types of models is that they are suitable for most data. But one disadvantage is the fact that they require programming and sometimes this requires extensive knowledge. To get started, let’s start off with a very brief explanation of each.
Click Here to Read More...
About the Creator
Technogibran
www.technogibran.com is a blog about technology and the Health.
Keep reading
More stories from Technogibran and writers in 01 and other communities.
IT Cybersecurity at Home | Hard but not Impossible
The world is evolving and changing rapidly. With the growing use of online resources, people are more vulnerable to cybercrime than ever before. We believe that no matter what happens, we will always have our own privacy. Because there are many ways you can protect your personal information online. Click here to Read Also...
By Technogibranabout a year ago in 01
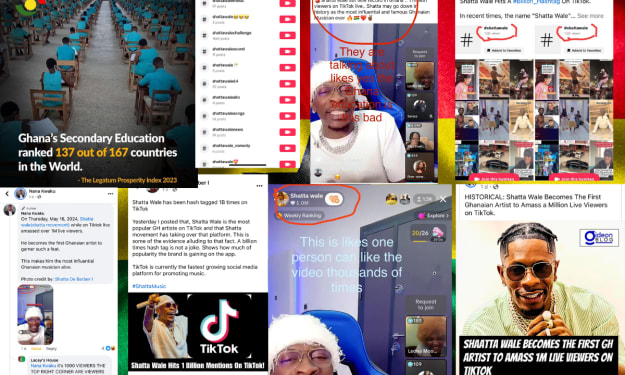
One of Ghana's False Viral Posts Highlight The Power of Social Media Misinformation
Sunday, 19 May 2024 By TB Obwoge I will break down that with better education and social media platforms stricter rules on sharing misinformation, there would be less posts like this one. Facebook, Twitter and TikTok are very lazy when it comes to users posting fake news and misinformation.
By IwriteMywrongs3 days ago in 01



Comments
There are no comments for this story
Be the first to respond and start the conversation.