
Text Annotation vs. Text Labelling: What Sets Them Apart in NLP?
In NLP, text annotation and labeling are vital tasks with distinct purposes. Annotation adds detailed information to text, aiding tasks like sentiment analysis and named entity recognition. And labeling categorizes text for tasks such as spam detection and topic modeling.


•Text annotation and text labeling are essential techniques in Natural Language Processing (NLP) for training AI and ML models.
•Text annotation involves assigning labels to text, providing context, while text labeling focuses on identifying relevant data and meaningful features within a dataset.
•The choice between them depends on your specific needs, project complexity, and available resources.
Text data analysis is a fundamental process across various industries. The surge in digital communication, particularly on social media platforms, has resulted in an overwhelming amount of unstructured text. To effectively handle this influx, it's critical to employ natural language processing (NLP) and other related techniques to unearth the value hidden in the data.
Text annotation is essential for converting unstructured data into structured formats that algorithms can process.
It can be confusing when terms like text annotation and text labeling are used interchangeably. Although they seem similar, they have subtle but important differences. However, these differences are often overlooked. Understanding these is the key to improving the performance and precision of data-driven applications.
Understanding text annotation
What is meant by text annotation?
In text annotation supplementary information is added for the text data, which aids in its understanding or analysis. Machine learning and deep learning algorithms are required to comprehend and process text.
For instance, in sentiment analysis, annotators assign intensity scores to express the strength of the sentiment in each text. A review may receive a sentiment intensity score of 0.8, indicating a highly positive sentiment, or 0.2, indicating a mildly negative sentiment.
By allowing machine learning models to grasp the subtleties of sentiment variations, text annotation improves its ability to capture and interpret emotions within textual content.
What types of tasks are more suitable for text annotation than text labeling?
•Named Entity Recognition (NER): Identifying and classifying named entities (like names of people, places, and organizations) within text. In NER, you not only label the entity type (e.g., person, location), but also identify the boundaries of the entity within the text.
•Text Categorization: Text labeling is used to sort text data into relevant categories for efficient retrieval. In this process, labeled examples of documents with assigned categories serve as training data for machine-learning models.
•Authorship Attribution: Through annotated examples of various writing styles, machine learning models discern distinct patterns and vocabulary choices associated with specific authors. Accurate identification of text authors based on their unique writing traits aids in applications such as forensic analysis, plagiarism detection and understanding authorship.
•Text Clustering: Representative labels applied to clusters, such as themes or topics, aid in the organization and understanding of document groups. The labeled data is essential for training clustering algorithms, which enable stakeholders to discern patterns and relationships within unstructured text. The resulting clusters further aid in exploratory data analysis, information retrieval, and content organization.
•Binary Text Classification: Here, a binary label (typically 0 or 1) to input text based on its content is assigned. The process helps in tasks such as sentiment analysis, spam detection or identifying whether a document belongs to a specific category.
What are the differences between text labeling and text annotation?
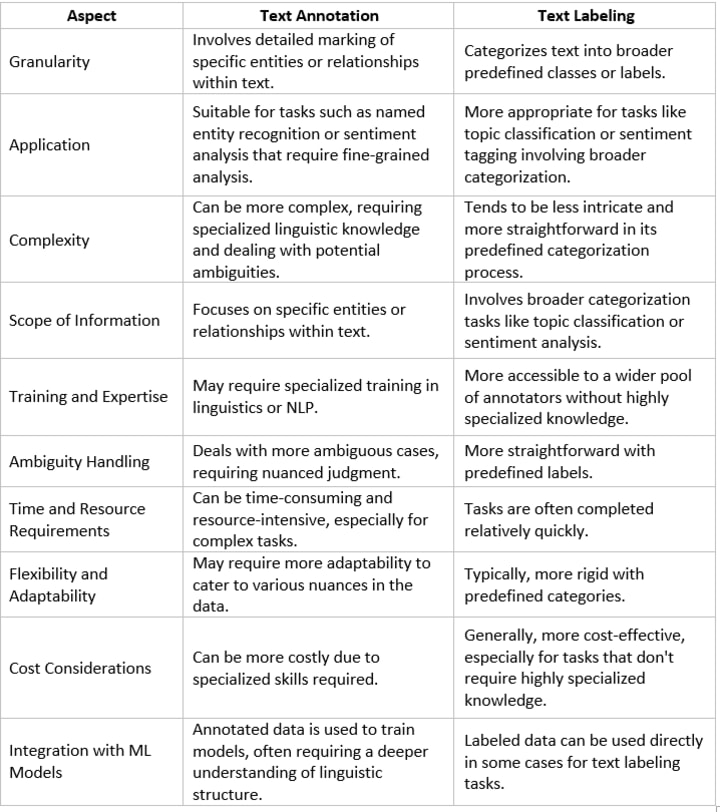
Text annotation workflow
As we can see, text labeling is just one process in the text annotation lifecycle.
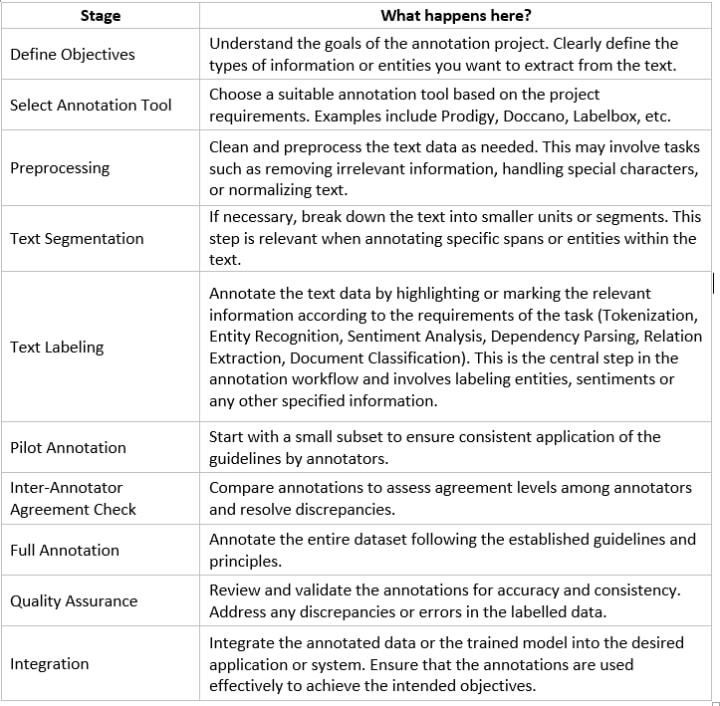
How to choose between text annotation and text labeling
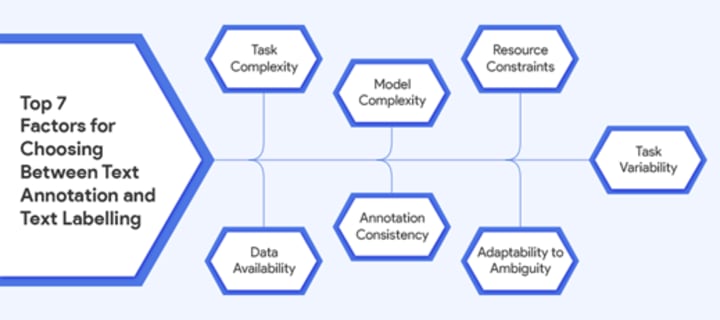
In certain cases, simple text labeling may not be adequate, while in others, expanding to additional dimensions of text annotation may be unnecessary. To decide which method to adopt, it is crucial to weigh various factors carefully. This process requires a detailed assessment to ensure the chosen approach aligns with the task at hand:
•Task Complexity: For nuanced tasks demanding a detailed understanding of text, opt for text annotation. It excels in tasks like named entity recognition or sentiment analysis. For simpler categorization needs, text labeling is more suitable, offering efficiency in topics such as sentiment tagging or topic classification.
•Data Availability: When pre-labeled data is limited, text annotation becomes crucial. It allows the creation of custom datasets tailored to specific needs. In contrast, text labeling can leverage existing labeled datasets, making it advantageous when abundant pre-labeled data is available.
•Model Complexity: For training complex models with a deeper understanding of linguistic nuances, text annotation is essential. It provides detailed information needed for advanced natural language processing tasks. Conversely, text labeling is suitable for simpler models that do not require intricate linguistic features.
•Task Variability: Consider whether the task requires handling a wide range of possible variations and scenarios. Text annotation offers greater adaptability to diverse nuances in the data, making it suitable for tasks with high variability. On the other hand, text labeling is more rigid, catering well to tasks with limited variations and predefined categories.
•Annotation Consistency: Text annotation allows for fine-tuning and maintaining consistency in the identification of entities or relationships within a text. This approach is crucial for tasks where uniformity is essential, such as in the legal or medical domains. Text labeling, while simpler, may lack the precision needed for consistent, detailed analysis.
•Resource Constraints: Consider resource limitations in terms of time and expertise. Text labeling, being less complex, is often quicker and more accessible, making it a pragmatic choice when faced with tight schedules or a limited pool of skilled annotators. Text annotation, which requires specialized knowledge, may pose challenges in resource-constrained situations.
•Adaptability to Ambiguity: If the task involves handling ambiguity and nuanced understanding, text annotation is preferable. It enables annotators to make nuanced decisions in cases in which the meaning may not be straightforward. Text labeling, being more categorical, might struggle with handling ambiguous situations effectively.
Conclusion
In-depth analysis is essential for businesses to determine whether text annotation or labeling fits their projects. The decision can be complex and involves various factors. Partnering with an external expert is often the best route.
A specialist in text annotation can quickly identify the right method for a task. Companies wanting to maximize their text data’s value should consider collaboration with experienced text annotation companies. This partnership ensures optimal decision-making regarding textual information.
About the Creator
Habiledata
Founded in 1992, HabileData is a leading provider of outsourced back-office services, including data processing services, data entry, and graphic design services.
Visit our website: https://www.habiledata.com
Keep reading
More stories from writers in Writers and other communities.
The Perfect Proposal on Yachts For Rent with The Yacht Brothers
As the sun set below the horizon, spreading a golden color across the Mediterranean waves, Sarah joined a beautiful yacht arranged by The Yacht Brothers. She was captivated by the yacht's smooth motion and the soft whispers of waves against its hull. The air was thick with the smell of salt and the promise of something wonderful.
By The Yacht Brothersa day ago in Writers
Music Prompt? Music Thingy!
At work a few weeks ago, I was using that Spotify DJ thing, the AI tool that slightly bugs me on principle, but not enough for me to boycott it. (You know the one?) Anyway, I was jamming out to songs I was familiar with, a few new ones, and then all of a sudden, I was stopped in my tracks.
By Mackenzie Davis5 days ago in Beat




Comments
There are no comments for this story
Be the first to respond and start the conversation.