
Pythagorean Yardage: A New Way to Evaluate CFB Teams
Tired of SRS and the AP Top 25? Here's a new way to look at your favorite football teams.


You’ve probably seen ESPN NY radio host Don La Greca’s rant against the use of the Pythagorean theorem in football. If you haven’t, you can watch it here. It’s highly amusing, especially considering that no one uses the Pythagorean theorem in football — most football players today learned it back in middle school (or at their senior year at UNC), and have never used it since. What La Greca might be trying to rant about is Pythagorean expectation: a formula used to predict a team’s win percentage based on point differentials. La Greca’s rant got me thinking — could we use Pythagorean expectation in football? And how can we apply it?
What is Pythagorean Expectation?
Pythagorean expectation originated from baseball sabermetrics, an invention of Bill James. The idea behind Pythagorean expectation is that a team’s run differential can be used to predict a team's win percentage. In other words, a team scoring more runs than they allow will tend to have a higher win percentage than a team that scores fewer runs than it allows.
There are three approaches to this problem — we can use a linear regression, a second order Pythagorean expectation, or a Pythagorean expectation using a specifically calculated exponent.
For linear regression, I downloaded CFB teams’ point differentials and used R to create an equation of a line that would predict their win percentage based on their point differential. This model, while fairly accurate, has significant limitations in that it allows for teams to have win percentages greater than 1 or less than 0.
I performed a similar calculation using a second order Pythagorean expectation formula – (Points scored)^2 / ((Points scored)^2+(Points allowed)^2) = expected win percentage. This equation fares better than the linear differential because it makes it impossible for teams to have win percentages greater than one or less than zero. However, using a power of two in the above equation is only an approximation — we can find the exact exponent to use with some algebra.
Setting our exponents in the above equation from “2” to “K” and solving yields that log (Wins / Losses) = K * log (Points Scored / Points Allowed), where K is a constant. We can use linear regression to solve for K, the exact exponent to be used based on a team's current Wins and Losses, such that our equation becomes (Points scored)K / ((Points scored)K + (Points allowed)K) = expected win percentage.
Expanding Upon Pythagorean Expectation
Pythagorean expectation is nothing new to football, and the Pythagorean expectation equation has been applied to a multitude of sports other than baseball. Rather than just rehash already-existing equations, I decided to explore new ways to look at Pythagorean expectation, especially in regards to football. I explored the relationship between win percentage and yardage differential, yards per play differential, and yards per point differential. I performed the same calculations as described above using these new variables — substituting in Yards gained for Points scored, Yards allowed for Points allowed, etc. and then looked at their accuracy.
Results from 2016
To test my methods initially, I used data of 2016 BCS teams from Sports References’ college football site. I downloaded the following sets of data on a team by team basis:
- Points scored
- Points allowed
- Total Yards of Offense
- Yards Per Play
- Yards Per Play Allowed
- Yards Per Point
- Yards Per Point Allowed
I then calculated each team's expected win percentage based on the differential for each metric: Points, Yards, Yards Per Play, and Yards Per Point. Using Root Mean Square Error, I then evaluated each model’s accuracy. For context, the closer RMSE is to zero, the more accurate the model is. As a point of scale, the RMSE of a traditional (second order) Pythagorean expectation for a decade of MLB scores is about 0.02.
RMSE of Win Percent Predictors for CFB Teams (2016)

As expected, the RMSE values for BCS teams in the 2016 season were significantly greater than the RMSE values for MLB teams. Since CFB teams play relatively fewer games than MLB teams, there is only a small range of win percent values for teams to fall upon (in a 13-game season, the only possible win percent values are multiples of 1/13 ranging from 0.000 to 1.000). However, for our purposes, the values in the exact-exponent Pythagorean are very accurate and give us a good picture of the strength of each BCS team.
The Argument for Using Pythagorean Yards
As evidenced above, using the exact-exponent Pythagorean method is superior, since it yields the best results by far. However, there are still merits to the other methods, specifically yardage differentials.
Presented below are several graphs displaying the normalized values of the rolling averages of points per game, yards per game, yards per play, and yards per point for teams in the 2016 season. In most instances, yards per game tends to normalize more quickly than any other value.
Normalized Rolling Averages for Georgia Tech

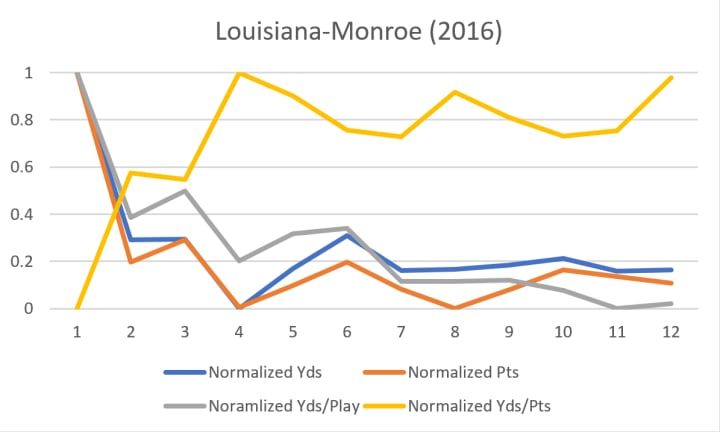


In general, the rolling average of yards per play and yards per point swing around drastically throughout the season, but points and yards tend to approach their final values more quickly, and yards tend to approach its final value more quickly than points (though this distinction is not quite as concrete as the assertion that yards per play and yards per point vary more than points and yards).
If we believe that our rolling average for yardage approaches its final value more quickly than points, then earlier in the season, our exact-exponent Pythagorean expectation based on yardage will be more indicative of a team’s end-of-season expected win-percent than the exact-exponent Pythagorean expectation based on points.
Any of the models with exact exponents, however, are technically appropriate to use. As a matter of personal preference, and not out of some quantifiable law, I prefer to use exact-exponent Pythagorean expectation for yardage compared mid-way through the season, and exact-exponent Pythagorean expectation for points approaching the end of the season. In general, the most accurate model is the exact-exponent Pythagorean expectation for points at the end of the season.
Evaluating Outliers
The model hardly fits every team exactly. Presented below are the residuals for each 2016 BCS team based on the exact exponent Pythagorean model for points. If a team has a residual above zero, that means it outperformed its expectation, and if it was below zero, that means it underperformed its expectation.
Residuals of EE Pythagorean Win Percent (2016)

The team that overperformed its expectation the most during last season was Idaho, who should have had a win percent of .491, but instead posted a win percentage of .692. Meanwhile, the team that underperformed the most was Notre Dame, who was expected to post a .560 win percentage, but instead finished with a .333 win percentage.
What causes teams to over/underperform Pythagorean expectations? Generally, performance in close games can cause teams’ overall win percentages to go out-of-skew with their expected win percentages. In 2016, Notre Dame was 1-4 in games decided by three points or less, but Idaho went 3-0 in such games. Such performances can account for the swings from expected win percent to actual win percent.
Performing poorly in close games can be largely attributed to luck, and is considered unsustainable. In general, teams that outperform or underperform their Pythagorean expectations one season find themselves regressing toward their expectation the next season. Indeed, Notre Dame is 5-1 in 2017, and Idaho is a mere 2-4 thus far this season.
Limitations of the Model
No model is ever 100 percent perfect, and Pythagorean expectation is no different. The residuals above should be evidence enough of this, but I want to take some time to address the limitations of the model in regards to college football.
The most obvious limitation is that, due to BCS’s small schedule, win percent values will fall into certain sets. Notice the residuals chart: each of the residuals falls into slanted lines, each representing a certain record. For a 13-game season, there will only be 14 possible win percent values – 0/13, 1/13, 2/13, etc. but Pythagorean expectations do not fall into such sets. Over a long season, such as baseball’s, these differences would be minimal.
Another caveat is that of “blowout games” and non-FBS opponents. If a team were to run up the score on a much weaker team (say, scoring 222 points while shutting out their opponents), its Pythagorean record will show it as being a much stronger team than it might be. However, the degree to which a team can beat up a weaker opponent is still indicative of the strength of a team. Also, since most teams only schedule one or two non-FBS opponents in a season, usually the impact of such games does not affect a team’s record (though I would certainly caution people about using Pythagorean records to evaluate teams three games into a season when one or two of those teams is non-FBS!).
It’s also worth noting the yardage model essentially assumes the odds of getting a third down stop or forcing a turnover are the same, regardless of field position. If a team’s defense consistently allows opponents to get to the red zone but makes red-zone stops, then that team will outperform its Pythagorean differential. If a team is consistently unable to capitalize on scoring while in the red-zone, then it will underperform its Pythagorean expectation.
The final major consideration is that Pythagorean record does not consider strength of schedule. In the future, I might like to look at calculating Pythagorean records while weighting differentials based on opponent SRS, or opponent Pythagorean expectation, but as it currently stands, this model does not consider opponent strength.
Even with these considerations involved, the model still performs admirably in determining a team's strength and expected win percentage.
Evaluating 2017 Teams
So far, we’ve dealt only with 2016’s data for the purposes of explaining each variable. We can use this data for the current college football season as well! Using the exact-exponent Pythagorean expectation for points, here are the top ten teams in college football.
- Penn State (expected W%: 1.000, actual W%: 1.000)
- Alabama (expected W%: 1.000, actual W%: 1.000)
- Washington (expected W%: 1.000, actual W%: .857)
- Ohio State (expected W%: 1.000, actual W%: .857)
- UCF (expected W%: 1.000, actual W%: 1.000)
- Georgia (expected W%: 1.000, actual W%: 1.000)
- Wisconsin (expected W%: .999, actual W%: 1.000)
- South Florida (expected W%: .999, actual W%: 1.000)
- Clemson (expected W%: .999, actual W%: .857)
- Virginia Tech (expected W%: .998, actual W%: .833)
You’ll notice there is very little differentiating the top teams; Penn State has an edge of only about .00001 over Alabama. But, I’m wary of any evaluation that doesn’t put Alabama directly on top. Remember what I said about how yards normalize more quickly than points? Let’s take a look at the top-10 teams from exact-exponent Pythagorean expectation for yards.
- Alabama (expected W%: 1.000, actual W%: 1.000)
- Ohio State (expected W%: 1.000, actual W%: .857)
- Georgia (expected W%: .999, actual W%: 1.000)
- Wisconsin (expected W%: .999, actual W%: 1.000)
- South Florida (expected W%: .999, actual W%: 1.000)
- Washington (expected W%: .999, actual W%: 0.857)
- Michigan (expected W%: .998, actual W%: .833)
- Oklahoma State (expected W%: .998, actual W%: .833)
- UCF (expected W%: .998, actual W%: 1.000)
- Penn State (expected W%: .997, actual W%: 1.000)
There’s slightly more differentiation present in the exact-exponent Pythagorean expectation for yards, and Alabama is at the top; this list “passes the eye test” a little bit more than the previous list. Again, though whichever expectation you wish to use is a matter of personal preference, as most of the exact-exponent models have comparable accuracy (though the point-based model is most accurate).
Which teams have been the least lucky this season? Here are the largest negative differences between actual win percent and exact-exponent Pythagorean expectation for yards.
- Massachusetts (expected W%: .533, actual W%: .000)
- Air Force (expected W%: .838, actual W%: .333)
- New Mexico State (expected W%: .919, actual W%: .429)
- Louisville (expected W%: .993, actual W%: .571)
- Texas (expected W%: .908, actual W%: .500)
These teams have underperformed in terms of wins and losses, but have consistently outgained their opponent in terms of total yardage. Moving forward, I would expect these teams to perform better than they have thus far this season.
The luckiest team this season are as follows, based off the largest positive difference between actual win percent and exact-exponent Pythagorean expectation for yards.
- Kentucky (expected W%: .226, actual W%: .833)
- Wyoming (expected W%: .073, actual W%: .667)
- Akron (expected W%: .044, actual W%: .571)
- South Carolina (expected W%: .225, actual W%: .714)
- California (expected W%: .083, actual W% .571)
These teams have managed to win a lot of games despite being significantly outgained — hardly a recipe for success. As a result, these teams are much weaker than their records might appear, and I would not expect them to find continued success in the rest of the season.
A note of caution: at this point in the season, some teams have a large divide between their Pythagorean expectation for yardage and for points. If you notice that a team has a large difference between the two, in evaluating them, I would exercise caution and look more closely at a team's overall strength. RMSE for the 2017 figures was approximately twice as large as it was for the 2016 season, because we have only half a season’s worth of figures presented. These figures should become more accurate as the season goes on.
Where’s My Team?
I have posted the 2017 results here. All data figures are up to date as of this week, and all data is from College Football Reference. This chart is sortable, so feel free to play around with these numbers! If there’s any interest, I can compile and post the results for 2016, or from any season dating back to 2000.
In the future, I hope to weigh differentials on the basis of the strength of teams to create a more accurate metric. For now, I’m satisfied with where the project is. I’ll try to keep this updated throughout the season!
Major thanks go to Chapman and Hall for their book, Analyzing Baseball Data with R, Bill James for inventing Pythagorean wins, and College Football Reference for its wonderful database.
About the Creator
John Edwards
Staff Writer for The Unbalanced, Contributor at Sporting News.
Keep reading
More stories from John Edwards and writers in Unbalanced and other communities.
It's Time To Talk About Fenway
Fenway Park is quite the odd beast. The Pesky Pole sits only 302 feet from home plate with about a four-foot high wall separating the fans from the field, and the Green Monster is, well, the Green Monster. The strange dimensions of Fenway have led to some memorable moments — Fisk waving it fair, Ortiz's incredible grand slam, etc. And now, we have Fenway to thank for possibly drastically changing the outcome of the ALDS.
By John Edwards7 years ago in Unbalanced
My Thoughts on a Possible 18-Game NFL Regular Season
The 2024 NFL Draft kicked off on Thursday, April 25, 2024, with the opening round, and during the coverage of the Draft, NFL commissioner Roger Goodell was interviewed. The interview saw something I had seen coming for a few years now: Goodell mentioned the possibility of the NFL's regular season increasing from 17 games to 18 games.
By Clyde E. Dawkinsa day ago in Unbalanced
Somers Defeats Hen Hud to Start 3-0
2-0 to start the season, Somers woke up early on Tuesday April 2 and fell behind 1-0 to visiting Hen Hud. “We started off a little slow,” said Grayden Carr, and the power outage holding for almost eight minutes, the offensive switch went on from the far end of the field.
By Rich Monetti4 days ago in Unbalanced
The Business of Nature
Dew drops reflected the light of the sun. The inhabitants of Whispering Woods woke up to the golden droplets of water on the leaves of the flora. The oaks particularly enjoyed the light and the maples did, too. Happiness enveloped all who lived there, even the rocks that cried out in the night delighted in the morning.
By Skyler Saunders4 days ago in Fiction




Comments
There are no comments for this story
Be the first to respond and start the conversation.