
The Next Frontier in AI Networking
The rapid arrival of real-time gaming, virtual reality and metaverse applications is changing the way network, compute memory and interconnect I/O interact for the next decade. As the future of metaverse applications evolve, the network needs to adapt for 10 times the growth in traffic connecting 100s of processors with trillions of transactions and gigabits of throughput. AI is becoming more meaningful as distributed applications push the envelope of predictable scale and performance of the network. A common characteristic of these AI workloads is that they are both data and compute-intensive. A typical AI workload involves a large sparse matrix computation, distributed across 10s or 100s of processors (CPU, GPU, TPU, etc.) with intense computations for a period of time. Once the data from all peers is received, it can be reduced or merged with the local data and then another cycle of processing begins.
Historically, the only option to connect processor cores and memory have been proprietary interconnects such as InfiniBand and other protocols that connect compute clusters with offloads. However, the scale and richness of Ethernet radically changes the paradigm with better distributed options now. Let's take a look at alternatives.
1. Ethernet NICs and Switches
Smart or high performance NICs often interconnect the sea of multiple cores in a network design. This is an emerging trend where the Network interface Controller (NIC) not only provides network connectivity but drives server offloads. The traditional design philosophy is to leverage general purpose GPU or DPU cores and interconnect with the right price/performance across memory and processors with accelerators such as RDMA (Remote Direct Memory Access). DMA is an operation to access the memory directly from the NIC without involving the CPU. Today’s NICs connect to Ethernet 10/100/200G switches, complementing the NICs, using a programmable framework often based on P4, such as the Arista 7170 series, as well as the 7050 series for more expanded memory and feature coverage.
2. InfiniBand
InfiniBand based switches and HBA (Host Bus Adapters) combine general purpose DPUs and GPUs to deliver consistent performance and can use RDMA offloads. Typical IB networks are vendor specific closed systems in high performance compute (HPC) use cases. The access on the responder throughput is limited by the InfiniBand (NIC and PCI). The low software dependency, decreases latency for InfiniBand versus TCP/UDP performance. However, smarter improved Ethernet switches and NICs also adopt non-TCP methods so the delta is narrowing between IB and Ethernet. Historically, InfiniBand was implemented in large supercomputer clusters but the high cost of scale-out and proprietary nature brings poor interoperability and limitations for AI and compute intensive applications.
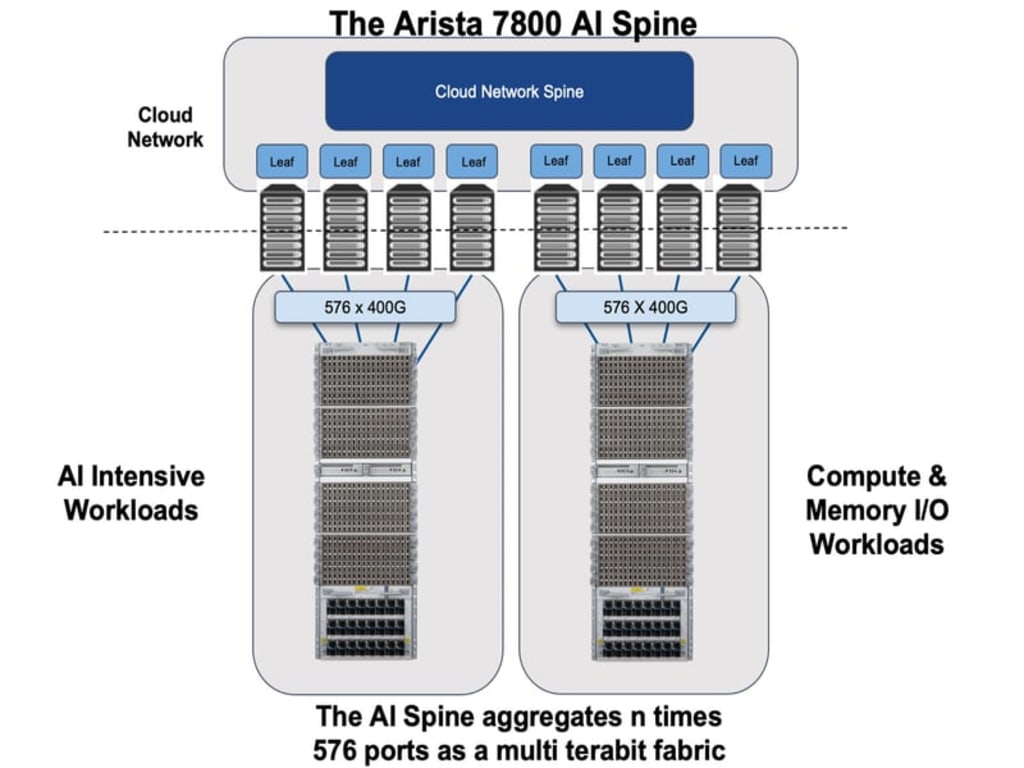
3. Ethernet-based Spine Fabric
The insatiable appetite for faster transfer latency and Ethernet as a preferred fabric between these processors is growing. AI processing grows exponentially for self-driving cars, interactive and autonomous gaming and virtual reality, mandating a scalable and reliable network.
Small packets with large flows make the Arista 7800 with EOS the ideal frontrunner combination. Designed with cell based VOQ (Virtual Output Queuing), and deep buffer architecture, the Arista 7800 is a flagship platform for high radix scale 100/200/400/800G throughput across all ports for efficient packet spraying and congestion control techniques such as ECN (Explicit Congestion Notification) and PFC (Priority Flow Control).
This new AI Spine delivers a balanced combination of low power, high performance/latency and reliability. The combination of high- radix and throughput of 400/800/Terabit Ethernet speed based on open standards is a winner! The future of AI applications requires more scale, state and flow in switches while maintaining simple standards-based compute for rack-automated networks. Compute intensive AI applications need open mainstream Ethernet fabric for improved latency, scale and availability with predictable behaviors for distributed AI processing and applications. Welcome to Arista’s data-driven network era powered by AI spines for next generation cloud networking!
About the Creator
Enjoyed the story? Support the Creator.
Subscribe for free to receive all their stories in your feed. You could also pledge your support or give them a one-off tip, letting them know you appreciate their work.
Keep reading
More stories from Stella Eric and writers in Families and other communities.
The Migration from Network Security to Secure Networks
The Migration from Network Security to Secure Networks Over the last few years, we have seen an age of edgeless, multi-cloud, multi-device collaboration for hybrid work giving rise to a new network that transcends traditional perimeters. As hybrid work models gain precedence through the new network, organizations must address the cascading attack surface. Reactionary, bolt-on security measures are simply too tactical and expensive.
By Stella Ericabout a year ago in Families
How to Poison Mother-in-Law?
Once a girl named Tabsum got married. She lived with her husband and her mother-in-law. Soon Tabsum realizes that she cannot live with her mother-in-law. The two had completely different personalities and Tabsum resented many of her mother-in-law's habits.
By Noman Khan2 days ago in Families




Comments
There are no comments for this story
Be the first to respond and start the conversation.