
Natural Language Processing Basics
Text Analytics using Python

Overview
Beginners guide to Natural language processing (NLP) using Python.
Introduction
According to industry estimates, only 21% of the available data is present in a structured form. Data is being generated as we speak, as we tweet, as we send messages on Facebook, Whatsapp, Chatbots, and in various other activities. The Majority of this data exists in the textual form, which is highly unstructured in nature. Few notorious examples include – tweets/posts on social media, user to user chat conversations, news, blogs and articles, product or services reviews, and patient records in the healthcare sector. A few more recent ones include chatbots and other voice-driven bots.
Despite having high dimension data, the information present in it is not directly accessible unless it is processed (read and understood) manually or analyzed by an automated system. In order to produce significant and actionable insights from text data, it is important to get acquainted with the techniques and principles of Natural Language Processing (NLP). This article will be a quick start for your journey in the NLP world!
Table of Contents
- Introduction to NLP
- Installation of required libraries
- Text Processing
- Parts of Speech (PoS) tagging
- Shallow Parsing
- Visualize Shallow parsed trees
- Illustration Using Brown Corpus
1. Introduction to NLP
NLP is a branch of data science that consists of systematic processes for analyzing, understanding, and deriving information from the text data in a smart and efficient manner. By utilizing NLP and its components, one can organize the massive chunks of text data, perform numerous automated tasks and solve a wide range of problems such as – automatic summarization, machine translation, named entity recognition, relationship extraction, sentiment analysis, speech recognition, and topic segmentation, etc...
Before moving further, I would like to explain some terms that are used in the article:
- Text object – a sentence or a phrase or a word or an article
- Tokenization – the process of converting a text into tokens
- Tokens – words or entities present in the text
I prefer to use Google Colab for Python instead of Anaconda because it provides more pre-installed machine learning libraries such as Keras, TensorFlow, and PyTorch. I have shared the Github link for the python code at the end of the article.
2. Installation of required libraries
Guys, if you are working on Anaconda jupyter notebook then you need to install nltk and spacy. Go to NLTK and SpaCy for installation help.
3. Text Processing
Consider the below sentence as an example.

We will separate all the words/entities present in the sentence to create tokens. There are total 11 words in the sentence.

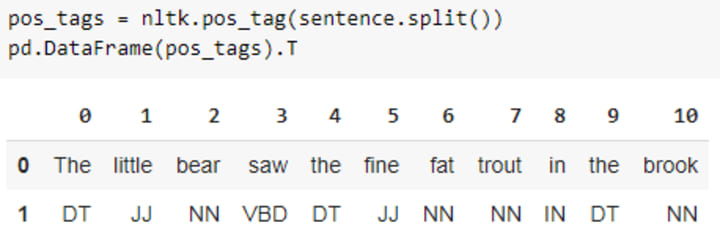
4. Parts of Speech (PoS) tagging
In simple words, POS tagging is a task of labelling each word in a sentence with its appropriate part of speech. We already know that parts of speech include nouns, verb, adverbs, adjectives, pronouns, conjunction and their sub-categories.
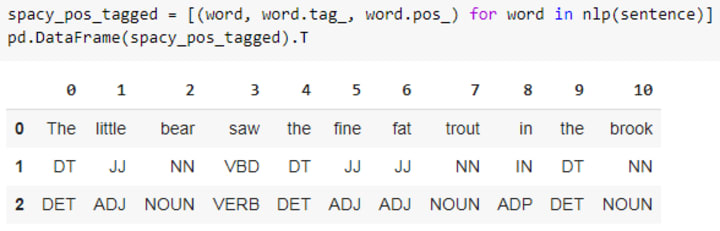
Firstly, we will find PoS tags for all the 11 tokens using nltk and then spacy.
Spacy gives tag and pos for each token.
5. Shallow Parsing
Typically we have a generative grammar that tells us how a sentence is generated from a set of rules. Parsing is the process of finding a parse tree that is consistent with the grammar rules – in other words, we want to find the set of grammar rules and their sequence that generated the sentence. A parse tree not only gives us the POS tags, but also which set of words are related to form phrases and also the relationship between these phrases.
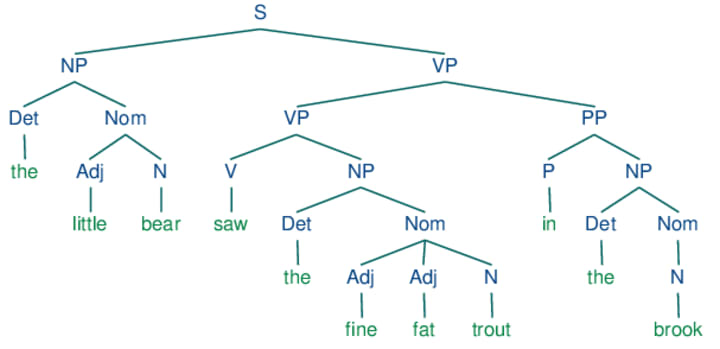
Shallow parsing is the process of being able to get part of this information (parse tree). POS tagging is like getting the last layer of the parse tree – only the part of speech tags like verb/noun/adjective… associated with individual words. Chunking another common technique gets the POS tags and which words are together to form phrases (This is like reading the last two layers of the parse tree).
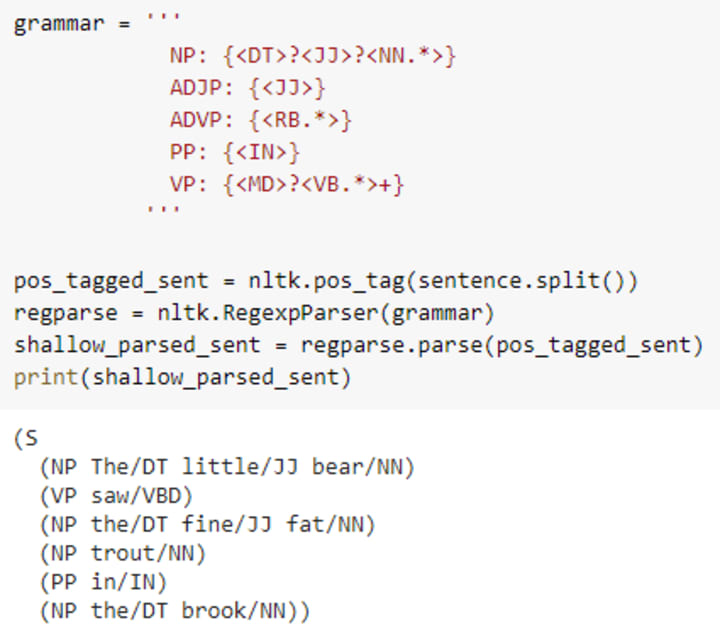
6. Visualize shallow parsed trees
First, we will visualize shallow parsed tree built using nltk followed by spacy.

We need to import displacy from spacy to render image.

7. Illustration
We will work on the fairly large corpus now. A corpus is a large and structured set of machine-readable texts that have been produced in a natural communicative setting. In simple words, Corpus refers to a collection of texts.
The Brown corpus is part of the NLTK data package. It's one of the oldest text corpuses assembled at Brown University. It contains a collection of 500 texts broadly categorized in to 15 different genres/categories such as adventure, news, humor, religion, and so on. This corpus is a good use case to showcase the categorized plaintext corpus, which already has topics/concepts assigned to each of the texts (sometimes overlapping).

Let us check the first 5 sentences of the 'adventure' category.

We will tokenize all sentences of 'adventure' category. Every sentence will be a list of tokenized words or tokens. Hence, corpus of 'adventure' category will be list of lists as list of sentences (where each sentence is itself just a list of words)!

Now every word or token will have its respective pos tag attached to it and every sentence will be in the form a list of tuple of word/token and pos tag. The tagged sentences will be list of list of such tuples.

Let us check the tagged words of the sentences.

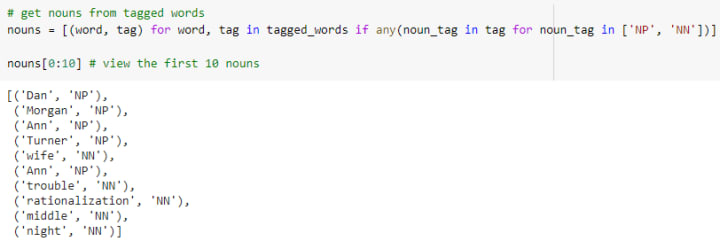
The first 10 nouns in the tagged words are below.
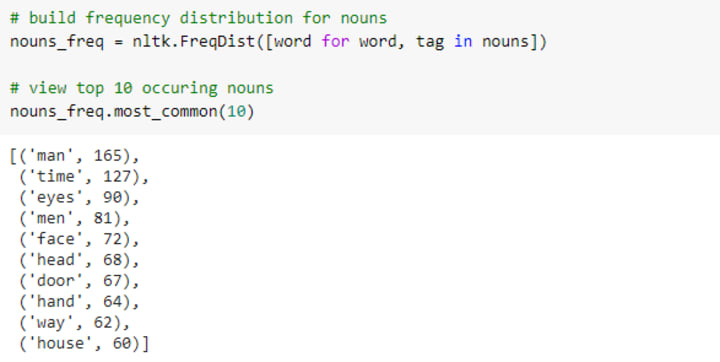
The top 10 occuring nouns by the frequency are below.
That's all in this article! I hope this will help you maximize your efficiency when starting with natural language processing in Python. I am sure this gave you an idea about basic techniques in NLP. Go to link https://github.com/Priyanka-Dandale/Natural-Language-Processing-2/blob/main/M1_NLP_Basics.ipynb for python code.
Happy Learning! :)
About the Creator
Enjoyed the story? Support the Creator.
Subscribe for free to receive all their stories in your feed. You could also pledge your support or give them a one-off tip, letting them know you appreciate their work.
Keep reading
More stories from Priyanka Dandale and writers in Education and other communities.
Machine Learning Model Performance Metrics
The idea of building machine learning models works on a constructive feedback principle. You build a model, get feedback from metrics, make improvements and continue until you achieve a desirable accuracy. Performance metrics as the name suggests explaining the performance of a model. An important aspect of performance metrics is their capability to discriminate among model results.
By Priyanka Dandale3 years ago in Education
The Evolution of LGBT Portrayal in TV and Film
Happy Pride Month, all! I love Pride Month and everything that comes with it; the celebration, the festivities, the prestige. Pride Month is the ultimate beacon of positivity. Now sadly, there are a bunch of people in society who aren't really crazy about Pride Month and have their things to say against it. To those people, I'll only say this. There's a special place reserved for people who are against Pride Month. I'm too much of a gentleman to say it here, but I'll give a few hints: it rhymes with "bell," and I'm not talking about the city in Michigan.
By Clyde E. Dawkins6 days ago in Pride




Comments
There are no comments for this story
Be the first to respond and start the conversation.