
Content warning
This story may contain sensitive material or discuss topics that some readers may find distressing. Reader discretion is advised. The views and opinions expressed in this story are those of the author and do not necessarily reflect the official policy or position of Vocal.
"Exploring Bernoulli Naive Bayes and Unveiling the Power of Out-of-Core Learning"
"Efficient Classification and Scalable Learning for Large-Scale Data Streams"

Before moving forward, you must have understood of below 2 posts.
post 1
Post 2
Agenda:
Now we are going to discuss the logic behind the Bernoulli Naive Bayes.
Additionally, we will also cover learning out-of-core Naive Bayes.
when to apply Bernoulli
when we have features, they contain binary data o (only two categories) either 0 or 1 it can also contain yes ,no,or true false we can easily convert it into 0 and 1
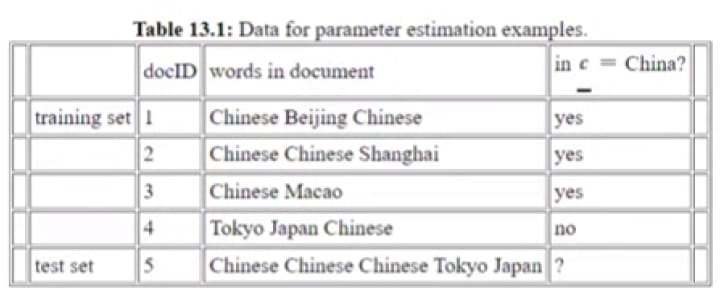
binary bag of word representation
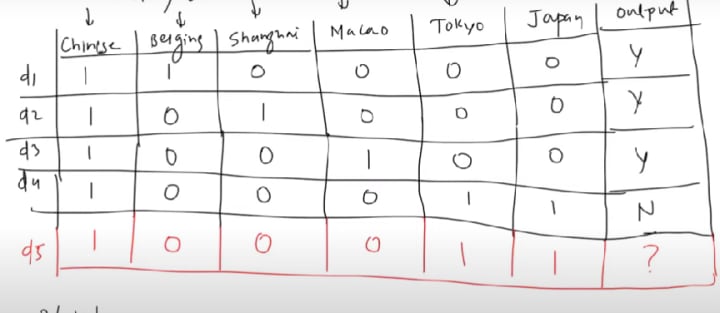
query point
d5 →{Chinese , Chinese, Chinese, Tokyo, Japan}
bag of words →{1,0,0,0,1,1}
we need to predict whether it is China or not.
= p (yes | Chinese=1, Beijing=0, Shanghai=0, Macao=0, Tokyo=1, Japan=1)
= P(Yes)*P(Chinese=1|Yes) * P(Beijing=0|Yes) * P(Shanghai=0|Yes) * P(Macao=0|Yes) * P(Tokyo=1|Yes) * P(Japan=1|Yes)
The Bernoulli formula is a mathematical expression used to calculate the probability of a binary event occurring. It is given by:
P(X = k) = p^k * (1 - p)^(1 - k)
Where:
P(X = k) is the probability of the event occurring as k (either 0 or 1),
p is the probability of success (the event occurring),
k can take either the value 0 or 1.
P(Yes)*P(Chinese=1|Yes) * P(Beijing=0|Yes) * P(Shanghai=0|Yes) * P(Macao=0|Yes) * P(Tokyo=1|Yes) * P(Japan=1|Yes)
1. P(Yes) = 3/4
2. P(Chinese=1|Yes) = p(Chinese=1) = p¹ * (1 - p)^(1–1)
p(Chinese=1) = p = 3/3
p represents the probability of Chinese=1 in the table, given "Yes."
3. P(Beijing=0|Yes) = P(Beijing=0) = p⁰ * (1 - p)^(1–0)
Here, p represents the probability of Beijing=1 in the table given "Yes," which is 1/3.
P(Beijing=0) = (1 - p) = (1–1/3) = 2/3
2. P(Shanghai=0|Yes) = P(Shanghai=0) = p⁰ * (1 - p)^(1–0)
Here, p represents the probability of Shanghai=1 in the table given "Yes," which is 1/3.
P(Shanghai=0) = (1 - p) = (1–1/3) = 2/3
3. P(Macao=0|Yes) = P(Macao=0) = p⁰ * (1 - p)^(1–0)
p represents the probability of Macao=1 in the table given "Yes,"
which is 1/3.
P(Macao=0) = (1 - p) = (1–1/3) = 2/3
4. P(Tokyo=1|Yes) = p(Tokyo=1) = p¹ * (1 - p)^(1–1)
p represents the probability of Tokyo=1 in the table given "Yes." which is 0/3
p(Tokyo=1) = p = 0/3
5. P(Japan=1|Yes) = p(Japan=1) = p¹ * (1 - p)^(1–1)
p represents the probability of Japan=1 in the table given "Yes." p(Japan=1) = p = 0/3
we can see we are getting probabilities =0 for Japan and Tokyo
After Laplace smoothing, the probabilities for "Tokyo" and "Japan" become non-zero. This is because Laplace smoothing adds a count of alpha=1 in numerator and n*alpha in denominator =2*1
here n is: 2, in Bernoulli we use 2 because no. of categories in Bernoulli is 2
Do the same calculation for below:
d5 →{Chinese , Chinese, Chinese, Tokyo, Japan}
P(No|d5) =
= p (No| Chinese=1, Beijing=0, Shanghai=0, Macao=0, Tokyo=1, Japan=1)
= P(No)*P(Chinese=1|No) * P(Beijing=0|No) * P(Shanghai=0|No) * P(Macao=0|No) * P(Tokyo=1|No) * P(Japan=1|No)
"Out-of-Core Naive Bayes: Handling Large-Scale Data Classification with Limited Memory"
Out-of-core Naive Bayes, also known as Incremental Naive Bayes or Streaming Naive Bayes, is an extension of the Naive Bayes algorithm that allows it to handle large datasets that cannot fit into memory. It achieves this by processing the data in smaller batches or chunks, rather than loading the entire dataset into memory.
The Naive Bayes algorithm is a popular classification algorithm based on Bayes' theorem, which calculates the probability of a class given the features of a data point. It assumes independence between features, hence the "Naive" in its name.
In the context of out-of-core Naive Bayes, let's consider a real-world example of email spam classification. Suppose you have a massive email dataset with millions of emails that you want to classify as spam or not spam. Since the dataset is too large to fit into memory, you need to use out-of-core Naive Bayes.
The out-of-core Naive Bayes algorithm would involve the following steps:
- Data Chunking: Divide the large email dataset into smaller chunks or batches that can be loaded into memory one at a time. For example, you can split the dataset into chunks of 10,000 emails each.
- Training Phase: Begin with the first chunk of emails. For each chunk, update the probabilities and statistics used by the Naive Bayes algorithm, such as the prior probabilities and conditional probabilities for each feature (e.g., words or word frequencies). This step involves counting the occurrences of features in the chunk and updating the probabilities accordingly. Repeat this process for each chunk of emails, incrementally updating the probabilities.
- Testing Phase: After training on the available chunks, you can test the out-of-core Naive Bayes classifier on new incoming emails. As each new email arrives, it can be processed individually and classified as spam or not spam using the probabilities computed during the training phase.
- Iteration: If there are more chunks remaining in the dataset, repeat steps 2 and 3 by loading the next chunk into memory and updating the probabilities accordingly. This process continues until all chunks have been processed.
By using out-of-core Naive Bayes, you can handle large-scale datasets that exceed the memory capacity of your system. It allows you to incrementally update the probabilities and statistics while processing data in smaller chunks, making it feasible to apply the Naive Bayes algorithm to real-world scenarios with massive datasets.
About the Creator
Enjoyed the story? Support the Creator.
Subscribe for free to receive all their stories in your feed. You could also pledge your support or give them a one-off tip, letting them know you appreciate their work.
Keep reading
More stories from ajay mehta and writers in Education and other communities.
From Novice to Expert: Woodworking
Embarking on beginning woodworking projects marks the start of an enriching DIY adventure for many enthusiasts. This journey from novice to expert in woodworking is not just about crafting wood into objects; it's an art that requires patience, precision, and a deep understanding of the material. The significance of these projects lies not only in the tangible creations they lead to but also in the skills and confidence they build. For individuals looking to dive into the world of woodworking, understanding the foundational aspects of the craft is paramount to their success and enjoyment.
By Daisy Rainbowa day ago in Education
VinFast vehicles from Vietnam
VinFast is a prominent Vietnamese automotive manufacturer that has rapidly gained recognition in the global market since its establishment in 2017. Known for its ambitious goals and innovative approach, VinFast has made significant strides in producing electric vehicles (EVs) and contributing to the transformation of Vietnam's automotive industry.
By LOC NGUYENa day ago in Education




Comments
There are no comments for this story
Be the first to respond and start the conversation.