
Types of Data Sets in Data Science, Data Mining & Machine Learning
and their general characteristics …


In one of my posts, I talked about what Data is and what do Data Attributes mean. This will continue on that, if you haven’t read it, read it here in order to have a proper grasp of the topics and concepts I am going to talk about in the article.
Please bear with me for the conceptual part, I know it can be a bit boring but if you have strong fundamentals, then nothing can stop you from being a great Data Scientist or Machine Learning Engineer.
There are three general characteristics of Data Sets namely: Dimensionality, Sparsity, and Resolution. We shall discuss what do they exactly mean one at a time.
What is Dimensionality?
→ The dimensionality of a data set is the number of attributes that the objects in the data set have.
In a particular data set if there are high number of attributes (also called high dimensionality), then it can become difficult to analyse such a data set. When this problem is faced, it is referred to as Curse of Dimensionality.
In order to understand what the hell is this Curse of Dimensionality, we first need to understand the other two characteristics of Data.
What is Sparsity?
→ For some data sets, such as those with asymmetric features, most attributes of an object have values of 0; in many cases fewer than 1% of the entries are non-zero. Such a data is called sparse data or it can be said that the data set has Sparsity.
What is Resolution?
→ The patterns in the data depend on the level of resolution. If the resolution is too fine, a pattern may not be visible or may be buried in noise; if the resolution is too coarse, the pattern may disappear. For example, variations in atmospheric pressure on a scale of hours reflect the movement of storms and other weather systems. On a scale of months, such phenomena are not detectable.
Now, coming back to the Curse of Dimensionality, it means many types of Data Analysis becomes difficult as the dimensionality (number of attributes in the data set) of the data set increases. Specifically, as dimensionality increases, the data becomes increasingly sparse in the space that it occupies. For classification, this can mean that there are not enough data objects to allow the creation of a model that reliably assigns a class to all possible objects. For clustering, the definitions of density and the distance between points, which are critical for clustering, become less meaningful.
Finally, coming on the types of Data Sets, we define them into three categories namely, Record Data, Graph-based Data, and Ordered Data. Let’s have a look at them one at a time.
Record Data

→ Majority of Data Mining work assumes that data is a collection of records (data objects).
→ The most basic form of record data has no explicit relationship among records or data fields, and every record (object) has the same set of attributes. Record data is usually stored either in flat files or in relational databases.
There are a few variations of Record Data, which have some characteristic properties.
- Transaction or Market Basket Data: It is a special type of record data, in which each record contains a set of items. For example, shopping in a supermarket or a grocery store. For any particular customer, a record will contain a set of items purchased by the customer in that respective visit to the supermarket or the grocery store. This type of data is called Market Basket Data. Transaction data is a collection of sets of items, but it can be viewed as a set of records whose fields are asymmetric attributes. Most often, the attributes are binary, indicating whether or not an item was purchased or not.
- The Data Matrix: If the data objects in a collection of data all have the same fixed set of numeric attributes, then the data objects can be thought of as points (vectors)in a multidimensional space, where each dimension represents a distinct attribute describing the object. A set of such data objects can be interpreted as an m X n matrix, where there are n rows, one for each object, and n columns, one for each attribute. Standard matrix operation can be applied to transform and manipulate the data. Therefore, the data matrix is the standard data format for most statistical data.
- The Sparse Data Matrix: A sparse data matrix (sometimes also called document-data matrix)is a special case of a data matrix in which the attributes are of the same type and are asymmetric; i.e., only non-zero values are important.
Graph-based Data
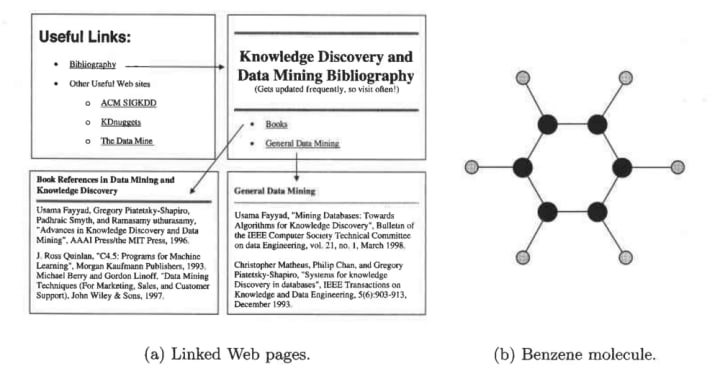
This can be further divided into types:
- Data with Relationships among Objects: The data objects are mapped to nodes of the graph, while the relationships among objects are captured by the links between objects and link properties, such as direction and weight. Consider Web pages on the World Wide Web, which contain both text and links to other pages. In order to process search queries, Web search engines collect and process Web pages to extract their contents.
- Data with Objects That Are Graphs: If objects have structure, that is, the objects contain sub-objects that have relationships, then such objects are frequently represented as graphs. For example, the structure of chemical compounds can be represented by a graph, where the nodes are atoms and the links between nodes are chemical bonds.
Ordered Data

For some types of data, the attributes have relationships that involve order in time or space. As you can see in the picture above, it can be segregated into four types:
- Sequential Data: Also referred to as temporal data, can be thought of as an extension of record data, where each record has a time associated with it. Consider a retail transaction data set that also stores the time at which the transaction took place
- Sequence Data: Sequence data consists of a data set that is a sequence of individual entities, such as a sequence of words or letters. It is quite similar to sequential data, except that there are no time stamps; instead, there are positions in an ordered sequence. For example, the genetic information of plants and animals can be represented in the form of sequences of nucleotides that are known as genes.
- Time Series Data: Time series data is a special type of sequential data in which each record is a time series, i.e., a series of measurements taken over time. For example, a financial data set might contain objects that are time series of the daily prices of various stocks.
- Spatial Data: Some objects have spatial attributes, such as positions or areas, as well as other types of attributes. An example of spatial data is weather data (precipitation, temperature, pressure) that is collected for a variety of geographical locations.
This concludes this post on types of Data Sets.
The follow-up to this post is here.
————————————————————————————————————
About the Creator
Tarun Gupta
A simple fellow writing stories, sharing experiences, sharing his perspective, trying to do his share of humanity.
Keep reading
More stories from Tarun Gupta and writers in 01 and other communities.




Comments
There are no comments for this story
Be the first to respond and start the conversation.