
How to Build a Privacy-Enhanced Document Reader for LLM-Powered Chatbot
Delivering Privacy and Security
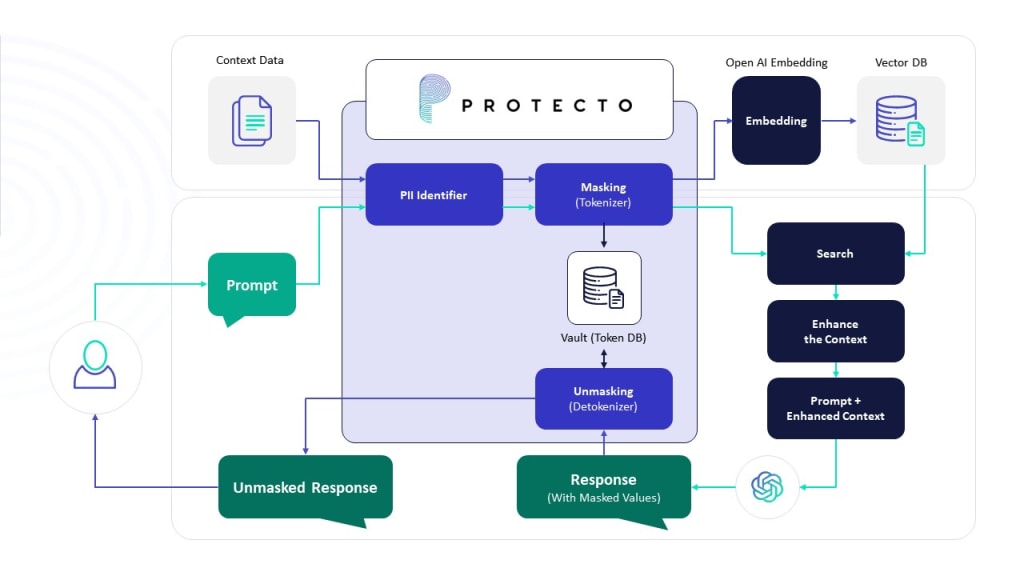
Delivering Privacy and Security using Protecto, LangChain, and OpenAI’s GPT
In the age of digital information, the development of chatbots and language models has revolutionized the way we interact with technology. One promising application of these innovations is the creation of document chatbots capable of extracting valuable insights from documents while safeguarding sensitive data. In this document, we will explore the critical role that Protecto plays in enhancing the privacy and security of such chatbots along with LangChain, and OpenAI’s GPT.
Why is this important?
Protecting user privacy and securing sensitive data is paramount in today’s digital landscape. Privacy-preserving chatbots, specifically designed to handle confidential information, are crucial for various industries, including healthcare, finance, and legal sectors. Here’s why Protecto stands out as the solution to these critical concerns:
Data Security: In any industry, safeguarding sensitive information (PII) is imperative. Protecto Privacy Vault empowers chatbots including any Large Language Models (LLMs) to derive insights from confidential records and documents while maintaining strict privacy standards. Its absence could pose significant challenges to organizations in adhering to privacy regulations.
Compliance: Many industries are subject to strict data protection regulations and compliance standards. Protecto ensures that chatbots or LLMs adhere to these regulations, mitigating the risk of costly legal consequences and reputational damage.
Internal Data Leaks: Protecto Privacy Vault safeguards against internal data leaks by masking sensitive details in chats or documents for LLM processing. The risk emerges when unmasking this data for user access. Protecto’s controlled unmasking feature is key here, ensuring secure data re-exposure, thus preventing potential data breaches and maintaining data integrity.
Enhanced User Trust: By using Protecto, chatbot developers can assure users that their data remains confidential and protected. This trust is essential for user adoption and satisfaction.
How It Works?
At its essence, a document chatbot operates much like OpenAI’s GPT. Just as with OpenAI’s GPT, where you can input text to request summaries or answers, the document chatbot involves extracting text from a singular document, such as a PDF. This extracted text undergoes a process of masking for enhanced protection and is subsequently fed into a finely tuned language model, akin to OpenAI’s GPT. This tuned model is specifically trained to recognize the tokenized text, empowering you to pose questions or seek information based on the content within the document.Embeddings and Vector Stores
We aim to efficiently distill pertinent information from our documents by leveraging embeddings and vector stores. Embeddings, serving as semantic representations, enable us to organize and categorize text fragments based on meaning. Breaking down our documents into smaller segments, we employ an embedding transformer to characterize each piece by its semantic essence.
An embedding provides a vector representation, assigning coordinates to text snippets. Proximity in these vectors indicates semantic similarity, facilitating the storage of embedding vectors in a vector store alongside corresponding text fragments.
With a prompt in hand, our embeddings transformer identifies the text segments most semantically relevant to it, employing the cosine similarity method. This method calculates the similarity between documents and a question, offering a robust means of associating prompts with related text snippets from the vector store.
This refined subset of information, now aligned with our prompt, serves as the context for querying the Language Model (LLM). By feeding only the relevant information into the prompt’s context, we optimize the efficiency of the interaction with the LLM, ensuring a more targeted and effective exchange.
Code:
Let’s install all the packages we will need for our setup
Initially, text extraction is performed using PDF Miner.
The extracted text is organized into ‘n’ lines and subsequently processed through the Protecto’s Tokenization API, where sensitive data, such as personally identifiable information (PII), is masked.
We use Protecto mask function to tokenize the PII data in the text
The sentence undergoes processing through split_text_with_overlap, a function that accepts the text, chunk size, and overlap as parameters. This function divides the entire text into specific chunks, ensuring each chunk contains an overlap of words to maintain contextual coherence.
We then create OpenAIEmbeddings to these chunks and Store the embeddings in a chroma DB.
About the Creator
Keep reading
More stories from writers in Lifehack and other communities.
Elevate Your Space: The Power of Interior Design
The creation of interior spaces is a kind of magic that works in the fast-paced world of interior design. Even though you are just about to renovate your home or redecorate your office interior design, interior design experts can produce an environment that motivates and works efficiently. Through the use of the newest gadgets such as the 3D room design, these maestros can make your vision a reality with the exactness and creativity that are needed.
By SpinHomes PVT LTD4 days ago in Lifehack
How to Read Anyone Instantly
How To Instantly Read Anyone: 8 Psychological Tricks We are inundated with information when we first meet someone. Determining their personality might be a challenging task. Because of this, it's critical to comprehend HOW we communicate. Experts estimate that only 7% of what we say really comes out of our mouths; the other 55% is communicated through body language and tone of voice. This implies that, in addition to what a person's outward look would imply, we must consider these three things when we first meet someone. Thus, beginning from the head down, notice the following cues to get a sense of someone's personality when you first meet them!
By Riza Faisal3 days ago in Lifehack
Vale Perficientur
"My tears need a minute to find the edges of my face. If you'll please excuse me." The sarcasm stabbed into Juliana’s heart. Antonia glared at her from the pit of the Lyceum as her student fought to hold back tears that had nothing to do with the pain in her fingers. “You’re better than this, again.”
By Matthew Fromm4 days ago in Fiction




Comments
There are no comments for this story
Be the first to respond and start the conversation.