
What OpenAI and Google fear most is a "smiling face"
AI Writes About AI


This article is generated by AI. I am starting an experiment to use AI to provide useful information. I aim to tryout AI’s writing ability. I made minimal changes to the content AI produced.
Please comment what you think about this article, or my experiment, or topics you’d like to see. Thank you.
"We have no moat, and neither does OpenAI".
In a recently leaked document, a Google researcher expressed this view. The researcher believes that in this fierce AI competition, although Google and OpenAI are chasing each other, the real winners may not come from these two, as a third force is emerging.
That force is the "open source community", which is Google and OpenAI's biggest enemy.
And the top player in the open source community is Hugging Face. As the Github of AI, it provides a large number of high-quality open source models and tools to maximise the benefits of research and development for the community, greatly reducing the technical threshold of AI and promoting the "democratisation" of AI.
Clément, One of Hugging Face’s founders, stated: In the field of NLP or machine learning, the worst case is to compete with the whole scientific community and the open source community. That's why we no longer try to compete and choose to empowering the open source and scientific communities.
Hugging Face was founded in 2016. It has raised 5 rounds of funding in a few years and its current valuation has risen to $2 billion. It has over 9.8 stars on Github and is firmly ranking among the popular resource libraries.
So what does this company do? How did it become the "top stream" in the open source world? What is its development model?
01 NLP paves the way for thriving
Hugging Face is an AI startup with natural language processing (NLP) technology at its core.
It was founded by French serial entrepreneur Clément Delangue (who founded note-taking platform VideoNot.es, media monitoring platform mention, and mobile development platform Moodstocks, which was acquired by Google), together with Thomas Wolf and Julien Chaumond. The company was founded in 2016 and is headquartered in New York, USA.

The two founders, Clément Delangue and Thomas Wolf, are both experts in the field of natural language processing. As they continue to develop Hugging Face, they are considered pioneers in the modern field of NLP.
Their original intention in creating Hugging Face was to provide young people with an "entertainment" "open field chat bot", like the AI in the science fiction film "Her", which can chat with people about the weather, friends, love and sports games and other topics. You can gossip with it when you are bored, ask it questions, let it generate interesting pictures and so on.
Therefore, the name Hugging Face comes from a cute smiling face emoji with open hands.

On 9 March 2017, the Hugging Face app was officially launched on the iOS AppStore and received a lot of attention. It also received $1.2 million in angel investment from investors including SVAngel and NBA star Durant.
To train the chatbot's natural language processing (NLP) capabilities, Hugging Face built a resource library that accommodates various machine learning models and different types of databases, which helps train the chatbot to detect emotions in text messages, generate coherent responses, and understand different conversation topics.
At the same time, the Hugging Face team open-sourced the free part of their library on GitHub to gain development inspiration from user co-creation.
In 2018, Hugging Face was still lukewarm and started to share the underlying code of the application online for free. This move received an immediate positive response from researchers at well-known technology companies such as Google and Microsoft. They began to use these codes for AI applications, and this smiling face emoji has also become well known to AI developers.
Coincidentally, in the same year, Google launched BERT, a large-scale pre-trained language model based on bidirectional transformer, which ushered in the "involution era" of AI models.
In this general environment, Hugging Face started to provide AI model services and then ushered in its own "golden age".
First, it open-sourced PyTorch-BERT; then it integrated the pre-training model into the NLP field it had previously contributed, and released the Transformers library.
The Transformers library provides thousands of pre-trained models that support text classification, information extraction, question answering, summarisation, translation and text generation in more than 100 languages. With the Transformers library, developers can easily use large NLP models such as BERT, GPT, XLNet, T5 and DistilBERT to perform AI tasks such as text classification, text summarisation, text generation, information extraction and automatic QA, saving a lot of time and computational resources.
In short, the Transformers library provides ready-to-use models without the need for companies to re-develop, so many companies have started to use the Transformers library to apply the models to product development and workflow.
As a result, the Transformers library quickly became popular and the fastest growing AI project in GitHub's history.
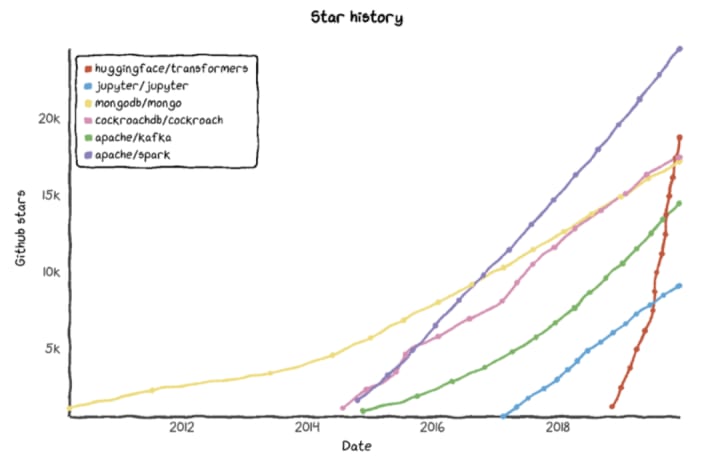
Clément couldn't help himself: "We didn't think too much when we released things, and the explosive growth of the community even surprised us.
With so many developers, Hugging Face created its own community, Hugging Face Hub. At the same time, it adjusted its product strategy, no longer limiting itself to natural language processing, but integrating different areas of machine learning to explore and create new use cases, and set out to build a complete set of open source products.
As of April 2023, Hugging Face has shared 16,6894 training models and 2,6900 datasets, covering NLP, speech, biology, time series, computer vision, reinforcement learning and other fields, building a complete AI development ecosystem.
This has greatly lowered the threshold for related research and application, making Hugging Face the most influential technology provider in the AI community.
So far, these models have served tens of thousands of companies for resource development, helping researchers and related practitioners to better build models and better participate in products and workflows, including Meta, Amazon, Microsoft, Google and other well-known AI teams.

Hugging Face is also very popular in the capital market.
In May 2022, the team completed a $100 million Series C funding round led by LuxCapital, with participation from Sequoia Capital, at a valuation that soared to $2 billion.
In the face of the capital hunt, Hugging Face's founders have remained extremely calm, saying that they have rejected multiple "meaningful acquisition offers" and will not sell the business like GitHub. The founders also have some interesting ideas about the future of Hugging Face: "We want to be the first company to go public with an emoji, not a three-letter ticker".
02 Github of machine learning
Hugging Face, which has made a name for itself through open source, has also paid special attention to community-building, and the recently launched Hugging Face Hub has become a stronghold for AI developers.
The Hugging Face Hub is a central place to explore, experiment, collaborate and build machine learning techniques. Here, everyone can share and explore models, datasets, etc., and everyone can easily collaborate to build machine learning models, which is why Hugging Face Hub is called "the home of machine learning".
It is the product of Hugging Face's adherence to "open source", and it is also its core. As the slogan on the official website states: AI community, building the future.
The founder of Hugging Face once publicly stated that "Hugging Face's goal is to enable more people to use natural language processing tools through tools and developer communities, to achieve their innovation goals, and to make natural language processing technology easier to use and more accessible".
He added: "No single company, including the tech giants, can 'solve the AI problem' alone, and the only way we can achieve this is by sharing knowledge and resources in a community-focused way."
As a result, the company is committed to building the largest open source collection of models, datasets, demos and metrics on Hugging Face Hub to 'democratise' AI by enabling anyone to explore, experiment, collaborate and build technology using machine learning.
Currently, Hugging Fac eHub offers more than 120,000 models (Models), 20,000 datasets (Datasets), and 50,000 demo applications (Spaces), all of which are open source, free and available.

Hugging Face Hub is open to all machine learning models and is supported by natural language processing libraries such as Transformers, Flair, Asteroid, ESPnet and Pyannote. Among them, the core natural language processing library is the Transformers library.
The Transformers library supports framework interoperability between PyTorch, TensorFlow and JAX, providing the flexibility to use different frameworks at each stage of the model lifecycle. In addition, the Inference API allows users to directly use the models and datasets developed by Hugging Face for inference and transfer learning. This allows the Transformers framework to reach an industry-leading level in terms of performance and ease of use, completely changing the development model of deep learning in the field of NLP.
In addition, the platform also provides some practical tools such as model version control, test integration, sharing and collaboration, etc., which can help developers to better manage and share models and datasets.
Therefore, in Hugging Face Hub, any developer or engineering team can easily download and train the most advanced pre-trained models through the interface, and use the reasoning API of thousands of models to solve common tasks in different modes, such as natural language processing, computer vision, audio, multimodality, and more, enable user to build a machine learning applications in minutes, eliminating the time and resources required to train models from scratch.
They can also create their own hub under their own accounts to store and share trained models, datasets and scripts, while sharing and communicating with the powerful community to easily collaborate to complete the ML workflow.
In short, Hugging Face Hub provides a platform for researchers to showcase the models they want to share and test the models of others to deeply study the internal architecture of these models and jointly promote the development of ML. In the past, AI seemed out of reach for front-end developers. After all, only a few code-generated AI systems have been freely available to the public.
Therefore, Hugging Face decided to provide open source models and APIs to the community to change this situation, taking the initiative to do the complex and detailed work in the process of AI research to application, so that any AI practitioner can easily use these study models and resources. In Hugging Face's own words, what they are doing is building a bridge between AI research and application.
In addition to providing convenience, Hugging Face is also actively taking steps to strengthen the security of the Hub to ensure that users' code, models and data are safe and that users can use it with confidence.
For example, model cards are included in the model library to inform users about the limitations and biases of each model, thereby promoting responsible use and development of these models; setting access control functions in the dataset allows organisations and individuals to review, create private datasets and handle access requests from other users.
It is also worth mentioning that in order to further "democratise" natural language processing technology, Hugging Face Hub also offers an NLP course - Hugging Face course.
This course uses the databases in the Hugging Face ecosystem (Hugging Face Transformers, Hugging Face Datasets, Hugging Face Tokenizers and Hugging Face Accelerate) to explain natural language processing (NLP) knowledge. It's completely free and has no ads.

In short, Hugging Face Hub is like the GitHub of machine learning. A platform driven by community developers that provides a wide range of resources, allowing developers to continuously explore, innovate and collaborate on machine learning models, datasets and machine learning applications, and to accelerate and advance AI development by sharing knowledge and resources.
03 "Open source" drives "Business"
So the question is, how does an "open source" company that provides a "platform community" make a profit?
First of all, open source is the right choice.
With the Transformers open source project, Hugging Face has accumulated huge influence, gathered a large number of developers to build a huge community Hugging Face Hub, and also won the trust of customers and investors, which made its commercial transformation naturally.
In this regard, Pat Grady, a partner at Sequoia Capital, also said: "They are prioritising application over profit, and I think that is the right approach. They see how the Transformer model can be applied outside of NLP, and they see how GitHub's opportunities are not just for NLP, but for every area of machine learning."
What's more, if you look at the entrepreneurial history of startups in the market over the past decade, you'll see a strong commercial validation of open source model. MongoDB, Elastic, Confluent and others are all open source companies with the fastest revenue growth. They have all achieved profitability and survived in the market.
Clément also firmly believes that startups can empower open communities in a way that can generate thousands of times more value than building a proprietary tool.
He even publicly stated, "Given the value of open source machine learning and its mainstream status, its usage is deferred revenue. Machine learning will become the default way of developing technology, and Hugging Face will become the top platform in this field, and generate billions of dollars in revenue."
Therefore, Hugging Face chose the commercial development path of "open source drives business", and started to offer paid features in 2021.

At present, Hugging Face's profitable businesses fall mainly into three categories:
- Paid Membership: Provide better services and community experience to gain benefits;
- Data hosting: According to different parameter requirements, different hourly charging hosting services are provided;
- AI Solution Service: The current flagship product provides customised solutions for customers towards NLP, Vision, etc. to get technical service fees.
Since 2020, Hugging Face has started to build customised natural language models for enterprises, and has launched personalised products for different types of developers, including AutoTrain, Inference API, Private Hub, Expert Support, etc.
Currently, more than 1,000 companies have become paying customers of Hugging Face, mainly large enterprises, including Intel, Qualcomm, Pfizer, Bloomberg and eBay.
In 2021, Hugging Face reached $10 million in revenue. Judging by the data, Hugging Face's "open source drives business" strategy is working.
This also confirms what Clément said: "The company does not need to receive 100% dividends from the value created. It only needs to realise 1% of the value. Even 1% is enough to make you a high-cap company".
In short, Hugging Face accumulated influence in the open source community and then gradually expanded into SaaS products and enterprise services. This gradual transformation has allowed Hugging Face to strike a good balance between open source and commercialisation, which is also an important reason for its success. This development strategy also makes Hugging Face unique in the AI world and sets an example for other AI startups.
However, the open source ecology also has its own weaknesses, as the development of commercialisation is likely to harm the natural growth of the community environment. In this regard, Hugging Face's approach is to strengthen the control of the technology and maintain its own open source ecology, while, at the same time, delving deeper into the field of scientific research.
"Machine learning technology is still in the early stages of development, and the potential of the open source community is huge. In the next 5 to 10 years, we will definitely see the rise of more open source machine learning companies," said Clément.
About the Creator
Daniel Williams
I am passionate about new technology. Posting stories is my newest experiment, I will use AI to post every article.
Keep reading
More stories from Daniel Williams and writers in Futurism and other communities.
An AI-Fueled Exploratory Passage into the World of Artificial Intelligence
This article is generated by AI. I am starting an experiment to use AI to provide useful information. I aim to tryout AI’s writing ability. I made minimal changes to the content AI produced. Please comment what you think about this article, or my experiment, or topics you’d like to see. Thank you.
By Daniel Williams12 months ago in Futurism
The Voyeur's Incandescent Reasoning
The woman sat nonplussed, in the Waiting Room. In a sort of daze, looking straight ahead patiently. She had already had three small breakfast's that morning and a nip of sherry, this was not unusual she would typically wait until an hour after she took her anti-depressant and was her morning routine. She was merely following instructions she assured herself, shifted slightly in her seat and feeling a little heart burn thought, maybe she should skip lunch. Dom had said to have the task done this week. She was well used to his methods and desired to get this over and done with soon. She glanced at her watch, smiled weakly at the Receptionist who was there for a moment and then gone.
By Canuck Scriber L.Lachapelle Author6 days ago in Fiction




Comments
There are no comments for this story
Be the first to respond and start the conversation.