

As a graduate of the University of Iowa's computer science program, I have an excellent background in the fundamentals of computer science. But I enrolled in the University over 10 years ago, when AI and its related sciences were just in their infancy. I had to learn a lot about what I know when it comes to AI on my own, which has been a great rollercoaster as there is so much information.
One of the current most frequently used types of AI or machine learning, is a neural network.
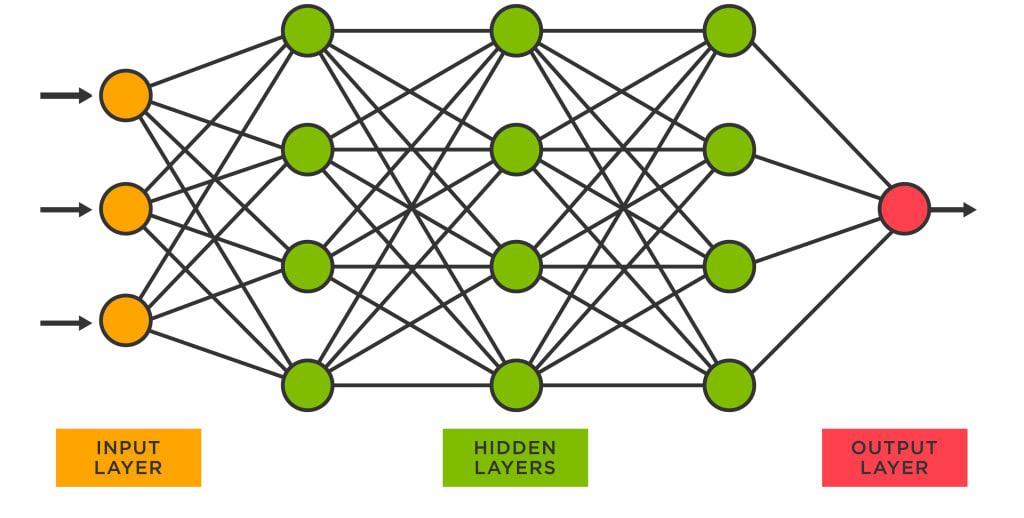
Neural networks are a type of machine learning algorithm that are inspired by the structure and function of the human brain. They are a fundamental building block of artificial intelligence (AI) and are used in a wide range of applications, from image recognition to natural language processing.
At a basic level, neural networks are composed of interconnected nodes or "neurons" that are arranged in layers. The first layer is typically the input layer, which receives data from the outside world. The data is then passed through one or more "hidden" layers, which process the data and make calculations based on the inputs. Finally, the output layer produces a result or prediction based on the input data.
The strength of neural networks lies in their ability to learn and adapt to new data over time. During the training phase, the network is fed a large amount of data and is "trained" to recognize patterns and make predictions based on that data. The network is then tested on new data to evaluate its accuracy and refine its predictions.
One of the key features of neural networks is their ability to "learn" from their mistakes. When the network makes an incorrect prediction, the error is calculated and the weights of the connections between the neurons are adjusted to reduce the error in future predictions. This process is known as backpropagation and is an essential part of training neural networks.
There are several different types of neural networks, each with its own strengths and weaknesses. For example, convolutional neural networks are particularly well-suited for image recognition tasks, while recurrent neural networks are better suited for sequential data such as speech and text.
Neural networks have become an essential part of AI and are used in a wide range of applications, including self-driving cars, virtual assistants, and recommendation systems. As the field of AI continues to grow and evolve, it's likely that neural networks will continue to play a key role in the development of intelligent systems.
What are the differences between the different types of neural networks?
There are several different types of neural networks, each with its own strengths and weaknesses. Here are some of the most common types of neural networks:
Feedforward neural networks: Feedforward neural networks are the simplest type of neural network and are often used for classification tasks. They consist of an input layer, one or more hidden layers, and an output layer. The network processes data by passing it through the layers in sequence, with no feedback loops.
Convolutional neural networks: Convolutional neural networks (CNNs) are particularly well-suited for image recognition tasks. They use a process called convolution to extract features from the input data and are able to recognize patterns and shapes within images. CNNs are often used in applications such as facial recognition and self-driving cars.
Recurrent neural networks: Recurrent neural networks (RNNs) are used for sequential data such as speech and text. They are able to remember information from previous inputs and use that information to make predictions about future inputs. RNNs are often used in applications such as natural language processing and speech recognition.
Long short-term memory networks: Long short-term memory networks (LSTMs) are a type of RNN that are designed to address the problem of vanishing gradients. Vanishing gradients occur when the gradient (i.e., the rate of change) of the error function becomes very small, making it difficult for the network to learn. LSTMs are able to remember long-term dependencies in the input data and are often used in applications such as speech recognition and machine translation.
Autoencoders: Autoencoders are a type of neural network that are used for unsupervised learning tasks such as dimensionality reduction and feature extraction. They consist of an encoder network that compresses the input data into a lower-dimensional representation, and a decoder network that reconstructs the input data from the compressed representation.
Generative adversarial networks: Generative adversarial networks (GANs) are a type of neural network that are used for generating new data based on a given input. They consist of two networks: a generator network that creates new data, and a discriminator network that evaluates the quality of the generated data.
These are just a few of the many types of neural networks that are used in AI applications. Each type of neural network has its own strengths and weaknesses, and the choice of which network to use depends on the specific task at hand. By understanding the differences between the different types of neural networks, AI developers can choose the best approach for their particular application.
What are the easiest NNs to use with Python?
One specific example of an easy neural network to use with Python is the Multilayer Perceptron (MLP) algorithm, which is part of the scikit-learn library. The MLP is a feedforward neural network that is widely used for classification tasks, such as recognizing images or categorizing text.
The scikit-learn library provides a simple and intuitive API for building and training MLP models in Python. Here's an example code snippet that demonstrates how to create an MLP classifier with two hidden layers:
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the digits dataset
digits = load_digits()
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size=0.2, random_state=42)
# Create an MLP classifier with two hidden layers
clf = MLPClassifier(hidden_layer_sizes=(64, 32))
# Train the classifier on the training data
clf.fit(X_train, y_train)
# Use the classifier to make predictions on the test data
y_pred = clf.predict(X_test)
# Calculate the accuracy of the classifier
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: %.2f%%" % (accuracy * 100))
In this example, the MLP classifier is used to recognize handwritten digits from the MNIST dataset. The code first loads the dataset and splits it into training and testing sets. It then creates an MLP classifier with two hidden layers, trains the classifier on the training data, and evaluates its accuracy on the test data.
This code demonstrates how easy it is to build and train an MLP classifier using the scikit-learn library in Python. With just a few lines of code, developers can implement a powerful neural network that can recognize complex patterns and make accurate predictions.
About the Creator
Ryan Kopf
I like clean living and going green. My passions include software architecture, future sciences, artificial intelligence, lifelong learning, the future of education and work, and more.




Comments
There are no comments for this story
Be the first to respond and start the conversation.