
How TikTok dances trained an AI to see
So Cool
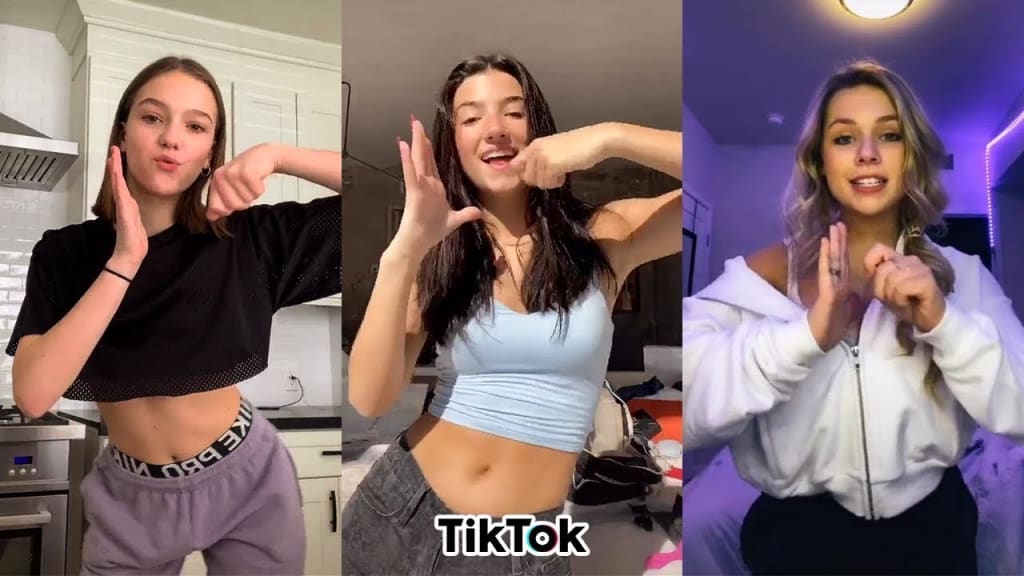
These are not MRIs.
They’re TikToks.
Hundreds of custom selected TikToks.
Different dances.
Indoors and outdoors.
Entirely different vibes.
But this is not to compare trendy dances.
It's to help computers learn to see.
So I want you to guess
why a wide range of Tik Tok videos
would be useful to help
a computer to see.
And try to remember your answer.
So I’m giving you this context first...
before I explain why this one researcher holed up in her room
finding 600 perfect TikToks.
It's not a bad dataset.
You get to watch a lot of dance videos, but after a while...
believe me, you get very tired.
Okay, so you hear about machine learning
and artificial intelligence
and maybe you imagine some machine
just vacuuming in all the world's information.
But a better analogy is flashcards.
On the front, you’ve got the question
on the back — the answer.
There are different data sets for different tasks.
For language, it's sentences
the model can learn to complete by checking the right answers
For an image generator
it would be a bunch of pictures with definitions.
These answers on the flashcards, they are called ground truth.
The computer can rely on them being right.
Now imagine all the stuff we want AI to do
from transcription to generating voices.
If you don't have answers on those flashcards...
ground truth, they're kind of useless.
And just like flashcards
the more varied and better your ground truth
the more an AI model can learn and test.
So here is the tricky part.
When do you train an AI on
if you want it to make three dimensional images
from two dimensional ones with just one viewpoint?
It's like a puzzle, right?
I mean, you need ground truth
to know if your AI or model is getting things right.
Yasamin started with Renderpeople.
It's this great dataset with ground truth...
because it includes video of people
and real 3D scans to go with it.
So you know exactly where they are in space.
An AI could look at these people
and learn how people work in 3D.
But there weren't enough flashcards there.
Yasmin and her coauthor didn't have enough backgrounds
enough variety.
We were interested in the motion.
We were interested in the movement of people.
How they appear when they move, and they go through different...
appearances and poses.
That sounds a lot like a TikTok.
Was that your guess why?
When I first saw this paper
I thought it was going to be because all the TikToks
were doing the same dance or something
but it's actually the opposite.
It's because all the TikToks are so different.
Yasamin knew that they'd be good for training since...
not only do they show people clearly...
they're also full of other stuff: backgrounds, jackets
different shapes.
To use them, Yasamin had to create a 3D picture.
She had the phone's point of view
so she used a program to remove the background...
and another program to estimate
how a person was moving in 3D space.
She ended up with 600 videos.
And her program could look at one part
see the depth, make a prediction
how the depth would look later, and check her work.
Like flipping over a flashcard.
I made my own TikTok dance called
“I cried in the shower this morning”.
And Yasamin was able to run it through her model
to create a 3D mesh.
But it gets weirder than that.
Do you remember this thing?
I paid Kim and Coleman a dollar each to do this
and if we used the right music, we would get demonetized.
But you know, the mannequin challenge.
It involved everyone from Hillary Clinton to James Corden.
It is the most James Corden-y thing imaginable.
But it is also a dataset.
Remember the flashcards?
Imagine you want computers
to learn to see depth in real situations.
You could set up tons of cameras in a circle to scan everything.
High, sky, straight on, like Renderpeople.
And you'd know all the angles.
But then you would lose the real world situation.
Or you can use the TikTok data to approximate ground truth.
But they are all moving around a ton.
If everyone is trying to stay still
it’s kind of like a bunch of cameras
taking pictures at the exact same time
with all the messiness of the real world built in.
It is a really interesting ground truth.
So Google researchers created “A Dataset of Frozen People”...
using tons of mannequin challenge videos.
2000 videos of people not moving
and that taught a model.
These became flashcards for a model to guess
if a camera moves five feet away, what a scene will look like.
These videos included tons of variety
variety in settings, types of people, everything.
It was gold.
It's like thousands and thousands of flashcards
for the model to learn from.
I spoke to a couple of researchers
who... sorry. Are we—
Are we done? Okay.
All right. Thanks.
Okay. So anyway.
They use the mannequin challenge not for training...
but to kind of grade how well their model did.
It was ground truth for them to evaluate their experiment.
One paper shows how to learn the geometry of a scene
to fill in missing parts in photos.
See how here they took an image, painted out part of it...
and then they use their knowledge of the scene
to fill it back in.
You can see the real angle here
and their program's version here.
One of the papers authors told me
the mannequin challenge helped them know
that they nailed it in any location.
We want to make sure this works for an image in the wild.
To use a randomly provided image
and you don't know if it’s indoor or outdoor.
Or you could be anywhere.
It was similar for the paper Virtual Correspondence
in which researchers figured out how to match points
in 3D scenes from different angles.
They could put in images
predict the pose and intersecting points
and match them up for everything from movie scenes
to scenes from Friends.
I like Friends.
I watch it more than ten times.
And then I thought, oh, maybe I can use this
this thing in my paper.
I screenshot screenshot and I just run it.
These researchers used the Mannequin Challenge
as ground truth to check their work.
And the many backgrounds
in the Mannequin Challenge were priceless
because the variety put their program through its paces.
Also, they checked their model against a Carnegie Mellon dataset too.
Where people stood in a big bubble filled with cameras.
This thing had perfect 3D scans of people in video.
It had ground truth, but the ground truth was still narrow
because it was in this sphere thing.
The Mannequin Challenge was in the real world.
Mannequin Challenge was like a full flashcard set...
with answers they could check.
Mannequin Challenge provides a nice thing
because everyone's kind of acting still
and then people go around the scene
so you can kind of get these extreme scenarios.
So what to make of all this weird stuff?
At first I was trying to get these researchers
to say how creative they are
but they were like, “It's not a big deal.”
But I will say this.
I highlighted the TikTok data set and the Mannequin Challenge
but those papers are also built
on top of this 3D Facebook dataset...
created by manually putting dots on people's faces.
And 10,000 real estate videos
that helped computers learn camera positions.
The machines: They are learning.
But for now, we are still the teachers.
They are only as good as the flashcards.
And we're the ones making them.
About the Creator
Keep reading
More stories from Fernando Cesar Cardoso and writers in Beat and other communities.
Frankie's Song of the Week: Espresso - Sabrina Carpenter
A little something different from me while I deal with the strain of writers block. I thought I'd do a song of the week, because I have been surely annoying my neighbours and my friends with this absolute musical GEM. I am of course talking about Espresso by Sabrina Carpenter.
By Frankie Martinelli4 days ago in Beat
Pat Black: Unleashing Musical Talents and Enthralling Audiences
Introducing Pat Black, an emerging artist originating from West Chester, PA, whose musical odyssey has been propelled by an innate ardor for R&B, rap, and Afrobeat. Pat's undeniable aptitude, drawing inspiration from icons like 50 Cent and Michael Jackson, has propelled him into the realm of the music industry, where he continuously mesmerizes audiences with his distinct sound and innovative approach.
By Quentin Perera7 days ago in Beat




Comments
There are no comments for this story
Be the first to respond and start the conversation.