
Scraping Vocal
Parsing, scrolling, cursing, crawling...

I am somewhat of a passionate person. One morning, I’d wake up with an obsession, and for the following several days, I would nurture it and ponder whether I should do it or not. Sometimes, it actually takes much longer than several days for me to finally start doing what I had come up with in my head (weeks, months, even years). Sometimes I am lazy, sometimes I am really busy with other things. Oftentimes I am sort of scared to start a new project because: I may not succeed, or I'm afraid I'll get bored too soon, or I tell myself that there are a lot of other more important things to do (which I also eventually may not do because it's actually so very difficult to set priorities and decide what is more important, and what is less... So, why not just sit and chill, read a book, or watch a movie?)
But eventually, one day or another, I do breathe life into my small projects. Unfortunately, not all of them; some poor little things are doomed to never see the light of day. Yet, some of these projects and/or activities that I do undertake, thrive to become my hobbies. Here, I would like to share with you, reader, a story of how I scraped Vocal – a brand-fresh mini-project I challenged myself with.
I haven't decided whether my story should be a how-to guide, an essay, a confession, or anything else. Should I elaborate on the practical side of my project, or should I focus on its spiritual aspects? I guess I'll try to do a little bit of both. And it might just be another small challenge for me. Creative writing: combine genres, styles, and purposes of your writing to output a story that is worth people's attention.
I'll start with a confession: Vocal, I've scraped your web pages. Sure, it doesn't sound as impressive as hacking something. But I am not a magician, and also, of course, I'm a law-abiding citizen. No hacking! (As if I could do that.)
Several days ago, I did not know much about web scraping. I knew the term, I had a general idea of what it does. But I had a rather vague idea of what specific purposes it can be used for, and I absolutely did not know how to do it. To put it short, web scraping is the process of extracting various data of interest from websites, normally in an automated way. In other words, one can get the information from hundreds–thousands of web pages in let's say several minutes and analyze it: e.g., do market research, price monitoring, news monitoring, etc., etc.
I got interested in how it works quite a while ago. Before that, I got interested in programming and started to learn Python in my free time. That happened around 3 or 4 years ago. My estimate is that nowadays, many young people get interested in programming one way or another at quite an early age: at school or even in kindergarten. It wasn't my case, but eventually, I also came to this. A late bloomer. Back in 2020, when COVID times began, I was staying in Portugal for a one-semester exchange program. What started as a multi-national exposure, a lot of activities and events, and discovering a new country and its culture ended up with all of us being locked down behind four walls. I mention it here not to complain (we've all been there) but to embed a small advertisement of a wonderful book for those who want to learn Python programming language and computer science in general: Classic Computer Science Problems in Python by David Kopec. During the Corona lockdown, I had quite plenty of time to do things, and studying this book was one of them. Sometimes, I have nostalgia for the times when I had plenty of time, but more often, I am truly happy not to have plenty of this free time as it may result in procrastination and loss of discipline in the wrong hands. I'm afraid to admit, my hands are pretty wrong. But I'm getting off-track.
I'm majoring in natural sciences, that is, at the intersection of chemistry and biology. Occasionally, I try to ingratiate myself with biophysics, like a little dog, barking at it, striving to bite this high-hanging fruit. But to each their own. I'm an experimental scientist (or rather on my way to becoming one, learning the ways of how-to-be-one), thus I'm not a bio-/chemoinforrmatics guru, and won't become one. Therefore, my contact with programming started merely as a product of curiosity. The last time I played around with code was 8 months ago. Back then, right of a sudden, I got interested in how to visualize standing and traveling waves. This time, I finally ventured into the world of web scraping. As I mentioned above, it bothered me for quite a while, how it works. The first time I came to think about it was concerning a large number of research articles one who works in science has to scroll through regularly to find some useful information. Is it possible to facilitate the process through a little bit of automation? For example, you are interested in some specific topic, let's say posttranslational modifications of microtubules (something close to what I'm working on now for my master's project☺). You are working in a team of n people, and what you wanna do is distribute the recently published papers in this area among all team members so that you all read a bunch of papers, and then gather together and present the relevant to your research information to each other. Of course, one way to do it is to manually search for the articles, download their PDFs one by one, and then distribute them among your team members. But why not try and automate the process of searching the articles of interest by keywords and downloading them? In the meanwhile, as this routine work is being done, you can sit, drink coffee, and read Immanuel Kant. That was the approximate rationale behind my interest in the subject of web scraping. But eventually, I never came to carry out this project for a number of reasons I don't remember.
A few days ago, I had a dream... Well, I didn't. But I finally decided to pull the trigger on this venture. I discovered Vocal about half a year ago, and as I had a humble story-weaver dozing inside of me, I pretty much liked the concept of this platform. So, now, I occasionally write down my little thoughts here on Vocal; sometimes, I participate in the Vocal challenges with the hope of gaining recognition someday :D, sometimes, I just input some gibberish (mostly poetry). I'm not really seeking for growing the audience; at least, I almost don't make any effort to do that. I'm writing for myself, well, and for rare passers-by (thank you!) who find themselves on my pages. Anyway, what I am trying to say is that I chose to learn how to scrape the web using Vocal as my bridgehead just because I happened to know about its existence, and it looked to me as a nice playground to practice on.
I decided to write some code that would enable one to collect information about Vocal challenges submissions: how many submissions a specific challenge got, how many authors contributed to them, and how many stories each author submitted. Further, I wanted to get the texts of all those stories. How may it be useful? That's one of the first questions I ask myself when starting any new project of mine. Actually, personally for me, a simple answer “because it's fun” was just enough. But in this case, there can be (of course, just hypothetically) some real-world applications for my scraper mini-program I wrote that I will be talking about below.
I don't know how the Vocal team judges the stories submitted for the challenges, but my guess is that they don't open every single link to the story manually in order to read and evaluate it. There should be some automated workflow that simplifies this procedure for them (am I right?). The other thought that visited my head was that (at least as I see it) the jury committee who read and select the winning stories should not know the authors' names for their judgment to be completely free from any speck of subjectivity. How to implement this strategy in practice? Finally, from time to time, when I have the mood and the time for scrolling through all the submissions for this or that challenge to read the stories and discover new authors for myself whose writing resonates with me, every now and then, I come across stories that do not meet the challenge requirements. For example, in the recent Tautogram challenge, where one was offered to write a poem where every word starts with the same letter, on the first page of All the great submissions, three stories out of twelve are not tautograms. In total, there were 1772 submitted stories. But how many of them are actually tautograms? Is there a way to find it out and filter out all the stories that do not fulfill the criteria set by the challenge prompt without reading them all and doing the filtering manually?
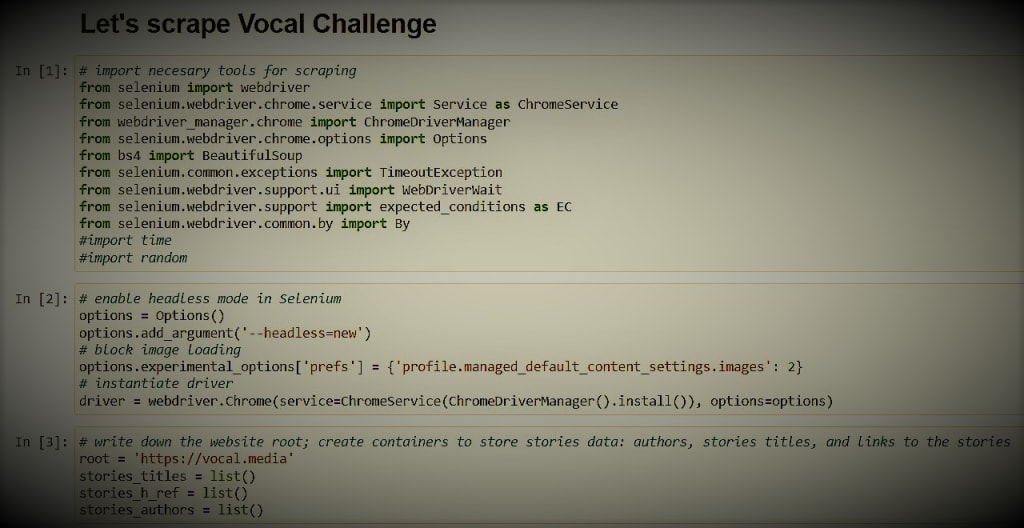
With these thoughts at hand, I started my work. The only programming language I'm familiar with relatively well is Python. Therefore it was chosen as my weaponry. My development environment of preference is Jupyter Notebook. It's interactive, easy to use, and just pretty (very objective description, isn't it?). But to run Python code with it, you need to have Python and its various libraries installed on your computer. Another option that does not require all this downloading-installing hustle is to use Google Colaboratory Notebook. It's very similar to Jupyter Notebook, but here Python and many of its libraries go preinstalled; thus, what you need is just to open your browser, navigate to the Google Colab web page, and you can start coding right away. Although, one might run into some problems while using it. I tried to use it for my web scraper but stumbled across an error when trying to instantiate a web driver that I could not resolve:
WebDriverException: Message: unknown error: cannot find Chrome binary.
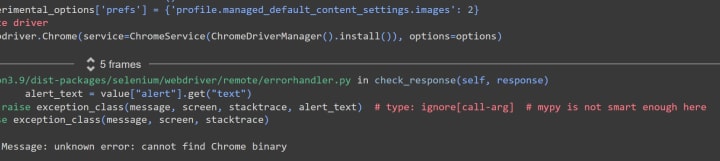
Searching the web didn't help me to resolve the problem. But probably, I'm just not smart enough. Although, I discovered that I wasn't the first to come across this problem (which is not that surprising; we all have much more in common than we know: common interests, common problems...). So, eventually, I returned back to Jupyter Notebook. Therefore, if somebody is now reading my how-to story and willing to play with my code (I'll share it at the end of my scribble), you'll have to have Python installed on your computer.
Now I'll go into a little bit of technicalities. I myself am far away from being an experienced coder and web scraper, so my explanations will be simplistic and maybe even somewhat vulgar. Sorry for that. Let's start.
Websites can be either static or dynamic. In the first case, each page on a static website is stored as a single HTML file, which is delivered directly from the server to the user exactly as is. The content of these web pages is "permanently engraved" on the screens of their visitors regardless of their age, location, religion, etc. unless the developer modifies the source code of each web page. In the case of dynamic websites, their web pages are flexible and can show different content to different users. Further, dynamic web pages can be either server-side or client-side. But all these details are not very relevant here. On one of the websites, while searching for explanations of what is what, I saw this nice clarification that makes it super easy to grasp the core of these two opposing terms — static stands for no users, no comments, no blog posts, no interactivity; dynamic provides us with all these benefits the modern society is so fond of.
It means that Vocal is a dynamic website. So far so good. Why is it important? Because for scraping static and dynamic websites one needs different tools. If, in the case of a static web page, you can directly extract its HTML file with all the data you might be interested in from the server, a dynamic website does not store each page as a separate HTML file. Therefore we cannot directly extract what does not yet exist. When one opens such a web page in their browser, the page content and thus also its HTML file is basically generated in situ or on the fly (whichever term you prefer). The server sends some (SOS) signals to some databases, and they exchange pleasantries; eventually, the server gets what it needs: the data to reconstruct the HTML file, the data is loaded dynamically with JavaScript into the user's browser, the browser humbly accepts this gift and finally spits out a personified web page which user can touch with their eyes. Well, that is approximately how I see how it works.
Thus, to do scraping of dynamic web pages one should have means to get access to full HTML files of those pages. The culprit that does not allow us to do it directly is JavaScript. There are two techniques to outsmart the opponent:
1) Reverse Engineering JavaScript, and
2) Rendering JavaScript.
Reverse engineering sounds like one definitely needs a degree in related areas to master it. Therefore, I decided to stick with the rendering method. To do so, one simply needs a "browser rendering engine that parses HTML, applies the CSS formatting, and executes JavaScript to display a web page."
We need a headless browser that would do all the dirty work for us!

A bit of surfing the Internet and I found just the right candidate for this job called Selenium. One nice tutorial on how to use it for web scraping that I found really useful can be accessed via this link.
Another tool I used for my scraping is called Beautiful Soup — a Python library for pulling data out of HTML and XML.
Thus, the framework for my code should be the following:
1. I obtain HTML from the web pages I want to scrape using Selenium.
2. Then I pass this HTML to my Beautiful Soup, and with its help, I pull the data I'm interested in.
3. To obtain data from multiple web pages, I just implement a loop that would feed my headless browser one page after another until it finally feels full. Actually, this step was a little bit tricky for me, as at first, I coded a loop that would run forever and wouldn't stop even after all the relevant data from the web pages were collected.
4. Then, finally, I can analyze my data. And here one can do a lot of things. For data analysis, I use yet another Python library called pandas. With its help, one can store all the extracted data in a sort of a table called DataFrame, and analyze it in ways similar to how one can analyze data stored in Excel sheets.
I chose to scrape the submissions for the recently closed Epistolary challenge. But in general, my code can be used for any other Vocal pages containing different stories, although then, in some cases, it would require certain modifications for it to run smoothly.
I wanted to extract the following information about every submission for the challenge: the story title, the author's name, the link to the story, and the story text itself.
If you go to the first page with the stories submitted for this challenge, scroll down to the end of the page, and navigate to the last page with the submissions, you'll see that there are 98 such pages, and each of them contains a “block” capable of accommodating 12 stories. That is 98*12 = 1176 stories. To be more precise, 1172, as the last block is not completely full. As you take a look at the address bar, you can notice that when you navigate from one page with challenge entries to another, the only thing that changes in there is the numbers at the end of the address: it goes from ...epistolary/submissions?page=1 to epistolary/submissions?page=98. So, I just need to loop through all of these 98 pages in my code. But what if I don't know in advance how many pages I need to loop through?
It's interesting that when you try to go to page number 99 in your web browser by directly typing the number in the address bar and pressing Enter, the newly uploaded page will greet you with "Something went wrong." But when you loop through the web pages in your code, the program doesn't stop at 98 but continues its idle work on and on and on. It won't tell you that page number 99 does not exist, but will impassively go on collecting data even though there is no more data to collect... But this problem can be easily solved by adding a kind of a switch inside the loop. It will be on all the time it sees that there is still data to collect, but as soon as the data (in this specific case, I mean the submitted stories) are no more, it switches off and lets the program know that it's time to stop. Speaking Python, I applied a while True loop, and as soon as all the stories data get extracted, True turns into False, the program reads a break statement and stops.
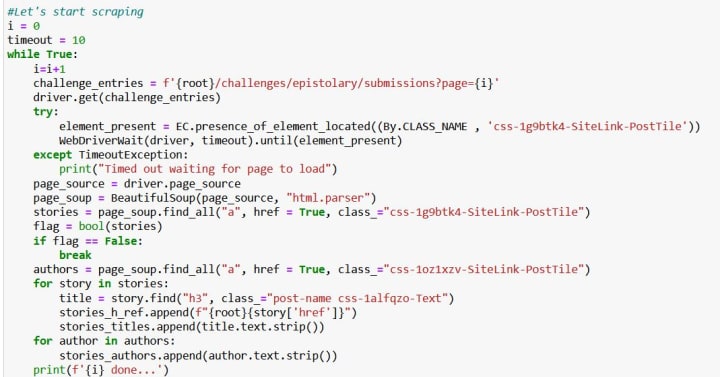
How to extract the authors' names, the titles of the stories, and links to them? HTML code is (of course) well-structured, and every element of the web page that we can see on our screens has its unique name and is called by it every time it appears in the code. For example, the "containers" with the links to the submitted stories, their titles, and short descriptions are defined by a class named css-1g9btk4-SiteLink-PostTile. Further, the stories' titles are hidden behind a post-name css-1alfqzo-Text class. Other elements of HTML code that one needs to include in their searching parameters are HTML tags. For example, <a> defines a hyperlink, <p> defines a paragraph, <h1> to <h6> defines HTML heading. With this knowledge and a few Python libraries, it's absolutely enough to start scraping any static or dynamic website. To find out the class name of your web page elements of interest, you should get an HTML file, open it and visually inspect it, looking for the names of what you're interested in to scrape.
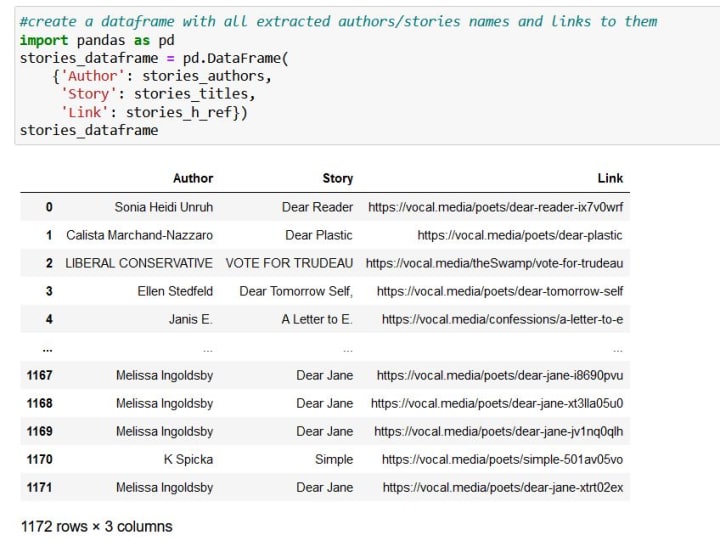
After running the code above, we've collected all the submissions for the Epistolary challenge. It's already enough to do some analysis. So, next, I created a pandas DataFrame with my downloaded stories info. And when I print out the table containing the collected data, I can see that it has 1172 rows. That is how many stories were submitted for the challenge.
Next, I wanted to see how many authors contributed to the challenge and how productive each of them was, how many stories they published:

Let's make it look a bit nicer:
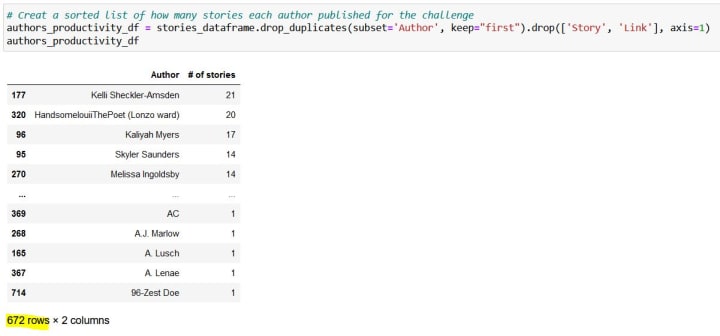
Kelli Sheckler-Amsden published 21 stories! Wow! Also, we can see that, in total, 672 authors participated in the challenge. We can continue playing around and look for any authors we might be interested in to see if they published any stories for the challenge.
But let's proceed with our scraping and get some more data! During my first scraping run, alongside the titles of the stories, I also got links to them. So let's now extract the full texts of all 1172 stories.
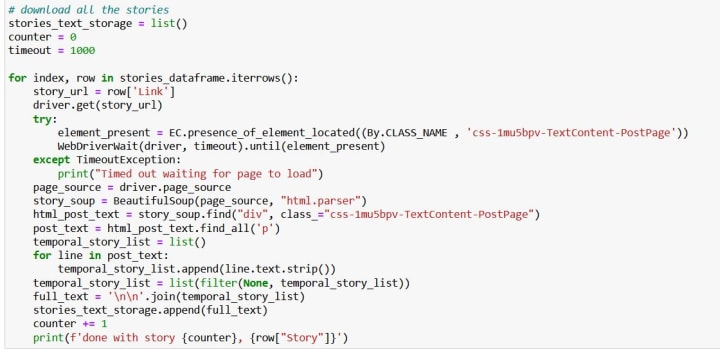
Here, I encountered another small issue. Occasionally, my headless browser wasn't able to load the page HTML code fast enough, and then my program broke down halfway, as my Beautiful Soup could not find the items I told it to look for, in this case, a class named css-1mu5bpv-TextContent-PostPage. At first, I came up with a rather barbarian method of waiting until the page loaded just by implementing time.sleep() right after my driver.get(story_url) command. I set the time for sleep to be several seconds; this short slumber gave the driver an opportunity to load the page, but still, the amount of time was not always enough. The problem with this method is that it enabled me to set only a strictly specified amount of sleeping time. But some pages load faster than others, some slower; therefore, it would be great to have some flexibility here. And WebDriverWait function is just what you need to make it work nicely and smoothly. Yet, I had to play around with the timeout value and eventually just set it to be quite large. Interestingly, if I run my code in the afternoon, it takes significantly less time to load all the pages and collect the data than in the evening.

After all the stories were collected, I added a new column with the full texts of the stories to my DataFrame. And, yay, we have now everything beautifully stored in one place. Now, we can, for example, find the stories of the writers we'd like to read and print them all out on the screen or save them to a Word document. I sketched some code to do that, but it totally neglects the original formatting of the stories. Though, with some additional work, it of course can be improved.
But what is much more interesting is to start analyzing the texts! What is the word count of each story? How many unique words it has, that is, how rich is its vocabulary? How many of the stories start with "Dear"? Or how many of them mention depression? Ultimately, it would be super cool to develop a tool that can recognize the stories that don't meet the challenge criteria and filter them out. But for the Epistolary challenge, it's not that easy. Even for the Tautogram challenge, it would be somewhat challenging, as, for example, some authors write a foreword or an afterword to their stories submitted for the challenges. Those should be recognized and not taken into account when checking if all the words in the stories start from the same letter.
But for now, let's just answer my 3rd and 4th questions.
How many stories start with "Dear" or "dear"?

That would be 837!
What about depression?

Just 23. Good! Wait? Did we count everything?

Nope, not really! We forgot about a CAPSLOCKED DEPRESSION. Phew, only one more...
Dear people, I hope you were just writing about depression but not really experiencing it! Otherwise, get better soon, please!
***
I'm just about to finish my story here. Congratulations to me: I killed my entire weekend! But it was fun. Hope this story of mine will find at least a few readers.
Also, I would like to apologize to Vocal for scraping it without asking for permission. But Google told me that it's not illegal if the data is stored in the public domain, and as long as I only use it for personal use. Still, if the Vocal team finds this behavior inappropriate, please implement some anti-bot detection technologies to create an additional level of protection against my kind. Although, personally I'm done with web scraping. No longer interested. It was fun, but I have some serious things to do.
Thank you for reading everyone who has come to this closing statement. I hope you don't feel that you wasted your time.
Cheers.
***
As promised, I share a link to my code.
About the Creator
Enjoyed the story? Support the Creator.
Subscribe for free to receive all their stories in your feed. You could also pledge your support or give them a one-off tip, letting them know you appreciate their work.
The Art of Work: Valuing Time in the Age of AI
Artificial intelligence isn't going away. You might be excited about that. You might be anxious. Whatever you're feeling, though, AI has become a permanent fixture in our society. As long as there's profit to be made, advancements in AI will shape the next wave of technology.
By Addison Horner25 days ago in 01
Navigating the Schengen Visa for UAE Residents Process
For UAE residents, traveling to Europe is an enticing prospect, offering a blend of history, culture, and natural beauty. However, one crucial step to making this dream a reality is obtaining a Schengen Visa for UAE Residents.
By Travnook Travel & Tourism7 days ago in 01




Comments (8)
This is a great article! its amazing what you did with this programme.. and a bit scary. Although I'm sure this is done all the time but we just done realise it (browser plugins that compare pricing etc. like honey probably use scraping). back in school they taught us a little BASIC and a bit of HTML and it was fun. wish i continued with it. i like how you broke down the way you went about your programming adventure, and how you overcame the obstacles... a great read!
Wow! This was seriously interesting!
Not a programmer but love to learn new things. So very cool!
Whoa! This is actually quite impressive 😅 You dug up some pretty cool details. This was an interesting read - thank you!
I love this. It's all another language to m, but fascinating all the same 😁
Fascinating read. I am impressed with the analytics you’ve compiled. I always wonder why some of those spam entries aren’t removed. Really great work, your weekend was productive!
Interesting, hope the deep dive was fun! ☺️
This was absolutely fascinating! I knew that Vocal had to use some form of technology in order to filter through their stories. I'm sure they've implemented a code like what you have done. Thank you for sharing what you've learned and your process. Knowledge is, indeed, power.