

DBMS stands for Database Management System. So before we go forward to discuss the important DBMS interview questions let us try to understand what is DBMS all about.
DBMS is a tool which is used for efficiently storing and querying the data in a database. The need for DBMS arises from the fact that there is a voluminous amount of data generated every day most of which comes from consumers interaction with the web interface of online companies. The way the consumers surf through different pages of a website, access different links tells a lot about their choices, their favourites.
Determining customer behaviour is an important factor in providing a better customer experience. Now here DBMS falls into the picture, you would be required to regularly update the database with information such as the number of times the user visited the site, how long did user looked at an image, no. of click-throughs to a particular link etc.
Data has become the heart of decision making in companies. There is a huge demand for people who are prolific with SQL since analyzing data involves wrangling and wrangling involves a specific set of action on data which is done via efficient querying.
So, here I have discussed some of the most common DBMS Interview questions through which you will be able to refresh some concepts of DBMS.
What is Data Abstraction in DBMS? What are the three levels of abstraction in the DBMS?
Data abstraction is the approach used by developers to hide irrelevant details related to data in the database so that the user interaction with the database is more efficient and the user gets the necessary information without getting involved in complex details.
Three levels of data abstraction are:
1) View level: This is the highest form of data abstraction which describes how users interact with the database.
2) Logical level: This is the intermediate level which describes what kind of data is stored in each database.
3) Physical level: Lowest level in data abstraction architecture which describes how data is stored in the database.
Explain ACID properties.
ACID properties are essential for maintaining the integrity of data. These properties are used as parameters to assess data transactions in a database. These properties are defined as the following:
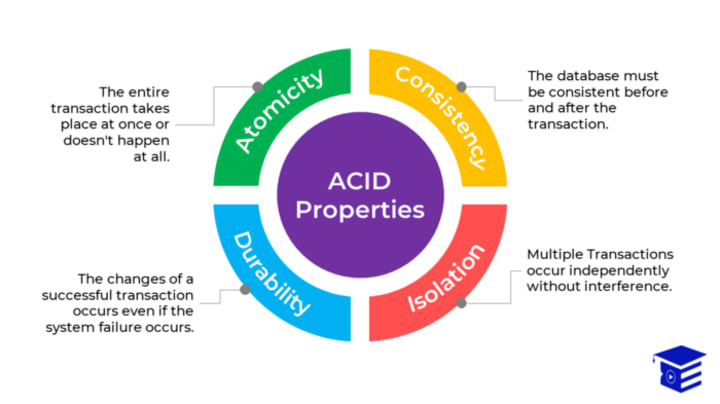
• Atomicity: The transaction should be either fully executed or shouldn’t be executed at all. Partial execution cannot happen.
• Consistency: A database should be consistent before and after the transaction.
For example, let’s say database A consists of bank accounts and from one of the accounts a1, 50 rupees is debited and credited into another account b1 which is stored in database B. if account a1 had Rs 100 initially and b1 had Rs 250 initially then before the transaction and after the transaction, the total sum of both accounts should be equal.
100 + 250 = 50 + 300
• Isolation: This property ensures that concurrent transactions which are happening on a database should not interfere with each other and occur independently. This property will prevent any inconsistency in data that may happen due to running multiple transactions simultaneously.
Durability: By durability, we mean that once a transaction is completed whatever changes, updates which are done to the database are stored in a disk. So that whenever there is hardware or software failure, the updates remain stored and aren’t lost.
What is normalization in DBMS?
Normalization is the process of analysing a database to avoid data redundancy across tables. In normalization, we break down a big table into smaller tables and then create links among those small tables to analyse better. Thus, normalization is helping minimize insertion, update and detect anomalies in a database.
Different types of normalizations are:
• First Normal Form, 1NF
• Second Normal Form, 2NF
• Third Normal Form, 3NF
Boyce & Codd Normal Form, BCNF
What is the 3-tier architecture in DBMS?
In 3-tier architecture, DBMS is divided into 3 levels:
• Physical Level: Tells us about where the data present in the database is stored in the secondary storage device such as disks and tapes with additional storage information. Users of DBMS are unaware of the details of the storage of data objects.
• Conceptual Level: Gives the representation of what type of data is stored in the storage device but intrinsic details related to the location are still unknown.
- External Level: This level is used to cater to the needs of different users who are accessing the database. For different types of users, data is presented in a user-friendly manner and in such a way, that they can interpret it conveniently.
What are the differences between DROP, DELETE and TRUNCATE?

What is the RDBMS?
RDBMS is a software which works upon the relational database. In a relational database, data is stored in form of tables which consists of rows and columns. The benefit of the relational database is that the data across different tables are related to each other so queries can be efficiently run over multiple tables in one go.
What RDBMS does is that it executes those queries on the database, for example, deleting, inserting or updating data stored in the table.
What is functional dependency?
For example, a store manager maintains a database of customers with attributes customer_id, customer_name, and customer_adress. Now here if we know the customer_id we also get to know customer_name. So here attribute customer_id uniquely determines the attribute customer_name and we say that customer_name is functionally dependent on customer_id. That is
customer_name -> customer_id
Hence, we say that the attributes of a table are functionally dependent if one attribute uniquely determines the other attribute.
What is Deadlock?
Ans: Deadlock is a situation where two or more transaction logs are indefinitely waiting for one another to give up on locks.
Deadlocks bring a halt to the whole database system until the deadlock is resolved.
How can Deadlock be prevented?
Deadlock can be prevented by avoiding entry into any of the 4 Coffman conditions:
• Mutual exclusion: No process has exclusive access to resources.
• Hold and wait: when a process holds onto a resource while waiting for another resource.
• No pre-emption: while the process is waiting for a resource, the program does not forcefully pre-empt the resource it holds, when a process is pre-empted.
• Circular wait: one process holds resources of other process and vice versa.
What is meant by query optimization?
Query optimization is an evaluation technique to find out the most efficient query for a task. The concept of query optimization is used when there are various algorithms and methods present for the same task and we want to obtain the one with the least cost.
Query optimization reduces time and space complexity which leads to executing a greater number of queries in less amount of time and provides the user with a faster result.
What are the different types of keys in DBMS?
Different types of keys in DBMS are:
• Primary key: Set of attributes used for identifying each record in the table. A table can have only one unique primary key and each row in that table is designated by a primary key value due to which it can get identified by primary key.
• Super key: Set of single keys or multiple keys which is used for identifying rows in a table.
• Candidate key: It is an attribute or set of attributes used for uniquely identifying tuples in a table.
• Foreign key: They are a set of attributes in a table which keeps references to primary keys of other tables. In this way, it establishes the link between the two tables
What is the difference between the WHERE and HAVING clause?
• HAVING clause is used to choose records from groups or aggregated row which satisfy given conditions while WHERE clause is used to choose records from the table which satisfies certain conditions.
- HAVING clause always require GROUP BY clause and is used after it but WHERE clause can still function without GROUP BY clause and when used with GROUP BY, is used before it.
What are different types of Join in SQL?
There are 4 types of join:
• Inner join: It returns a new result table after combining matching rows from two or more tables.
• Left join: It returns all rows from the left table and matching rows from the right table.
• Right join: It returns all rows from the right table and matching rows from the left table.
- Full join: It is a combination of both left and right join where all the matched rows of two tables are returned first followed by non-matching rows of two or more tables.
What is a Trigger?
Triggers are SQL statements that are automatically executed whenever there is a modification or update in a database.
They are automatically executed whenever an update is done or data is inserted or deleted in a database. In this way, the trigger maintains data integrity by allowing data changes systematically.
What are the differences between network and hierarchical data models?

So these were some of the commonly asked questions in DBMS. I hope you got some idea of the concepts asked in these questions. If you are interested to know about many more such questions feel free to visit here!
Thank you and have a nice day!
About the Creator
Satyam
Knows a thing or two about interviews
Keep reading
More stories from writers in Journal and other communities.




Comments
There are no comments for this story
Be the first to respond and start the conversation.