
Vectors are over, hashes are the future of AI
Vectors are over, hashes are the future of AI

Artificial intelligence has been built on the back of vector arithmetic. Recent advances show for certain AI applications this can actually be drastically outperformed (memory, speed, etc) by other binary representations (such as neural hashes) without significant performance trade off.
Once you work with things like neural hashes, it becomes apparent many areas of AI can move away from vectors to hash based structures and trigger an enormous speed up in AI advancement. This article is a brief introduction in to the thinking behind this and why this may well end up being an enormous shift.
Hashes
A hash function is any function that can be used to map data of arbitrary size to fixed-size values. The values returned by a hash function are called hash values, hash codes, digests, or simply hashes
You can read more about hashes here. The example from Wikipedia is illustrated below.
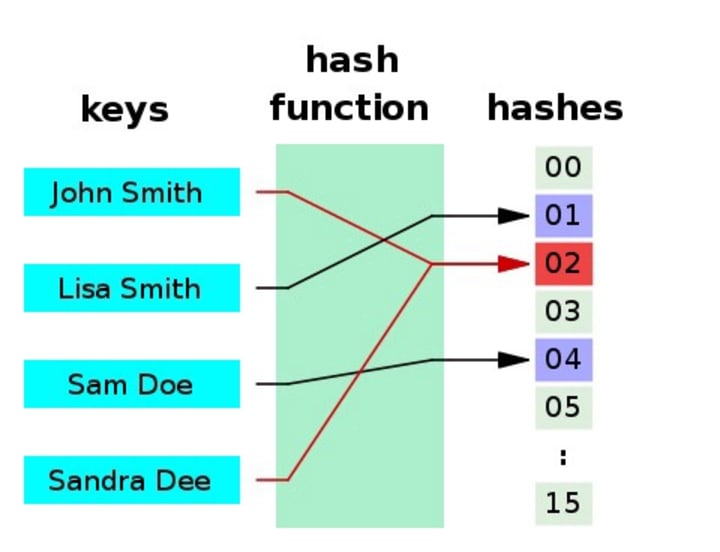
Hashes are great for trading off accuracy, data storage size, performance, retrieval speed and more.
Importantly they are probabilistic in nature so multiple input items can potentially share the same hashes. This is interesting because at the core the trade off is giving up slower exactness for extremely fast high probability. The analogy here would be the choice between a 1 second flight to somewhere random in the suburb of your choosing in any city in the world vs a 10 hour trip putting you at the exact house you wanted in the city of your choice. The former is almost always better, navigating within a suburb in 10 hours is a piece of cake.
When thinking about vectors, floats are the data representation of choice. Although they are more absolute in nature than hashes, they are still not exact either. More on floats below…
Floats
To understand AI you need to understand how computers represent non integer based numbers. If you have not read up on this, you can do here.
The problem with floating point numbers is they take up a decent amount of space, are pretty complex to do calculations with and are still an approximation. Watching Rob Pike talk about a bignum calculator was prob the first time I thought about it much. It’s bothered me a lot since. Thanks Rob 😁.
The binary representation can also be wildly different for tiny numerical changes (with respect to vector calculations) that have virtually zero impact on model predictions. For example:
Take 0.65 vs 0.66 which in float64 (64 bit floating point) binary can be represented by these two binary numbers respectively:
11111111100100110011001100110011001100110011001100110011001101
11111111100101000111101011100001010001111010111000010100011111
It’s not easy to see, but with just that 1% numerical change, almost half (25 of the 64 bits) are different! From a vector perspective in a matrix calculation these two numbers are very, very similar, but in the underlying binary (where all the heavy lifting happens) they are worlds apart.
Our brains definitely don’t work like this, so they obviously don’t use floating point binary representations to store numbers. At least it sounds like a stupid thing for neurons to do, except there are people that can remember over 60,000 decimal places of Pi, so maybe I have no idea. But seriously, our brains are visual and visually our brain’s neural networks are great at handling fractional numbers representing intensities and such. But when you think of a half or a quarter, I’ll bet you immediately visualised something like a glass half or quarter full, or a pizza or something else. You likely weren’t thinking of a mantissa and exponent.
One idea commonly used to speed float calculations up and use less space is dropping the resolutions to float16 (16 bit) and even float8 (8 bit) which are much faster to compute. The downside here is the obvious loss of resolution.
So you’re saying float arithmetic is slow/bad?
Not quite. Actually it turns out this is a problem people have spent their careers on. Chip hardware and their instruction sets have been designed to make this more efficient and have more calculations processed in parallel so they can be solved faster. GPUs and TPUs are now also used because they handle mass float based vector arithmetic even faster.
You can brute force more speed, but do you need to? You can also give up resolution, but again do you need to? Floats aren’t absolute either anyway. It’s less about being slow here but more about how to go much faster.
Neural hashes
So it turns out binary comparisons like XOR on bit sets can be computed much, much faster than float based arithmetic. So what if you could represent the 0.65 and 0.66 in a binary hash space that was locality sensitive? Could that make models much faster in terms of inference?
Note: looking at a single number is a contrived example, but for vectors containing many floats the hash can actually also compress the relationship between all the dimensions which is where the magic really happens.
Turns out there is a family of hash algorithms to do just this called locality sensitive hashing (LSH). The closer the original items, the closer the bits in their hashes are the same.

This concept is nothing new though, except that newer techniques have found added advantages. Historically LSH used techniques like random projections, quantisation and such, but they had the disadvantage of requiring a large hash space to retain precision, so the benefits were somewhat negated.
It’s trivial for a single float, but what about vectors with high dimensionality (many floats)?
So the new trick with neural hashes (or sometimes called learn-to-hash) is to replace existing LSH techniques with hashes created by neural networks. The resulting hashes can be compared using the very fast Hamming distance calculation to estimate their similarity.
This initially sounds complicated, but in reality it isn’t too difficult. The neural network optimizes a hash function that:
retains almost perfect information compared to the original vector
produces hashes much smaller than the original vector size
is significantly faster for computations
This means you get the best of both worlds, a smaller binary representation that can be used for very fast logical calculations, with virtually unchanged information resolution.
Use cases
The original use case we were investigating was for approximate nearest neighbours (ANN) for dense information retrieval. This process allows us to search information using vector representations, so we can find things that are conceptually similar. Hence why the locality sensitivity in the hash is so important. We’ve taken this much further now and use hashes much more broadly for fast and approximate comparisons of complex data.
Dense information retrieval
How many databases can you think of? Likely a lot. How about search indexes? Likely very few and most of those are based on the same old tech anyway. This is largely because historically language was a rules based problem. Tokens, synonyms, stemming, lemmatisation and more have occupied very very smart people for their entire careers and they’re still not solved.
Larry Page (google founder) has been quoted as saying search won’t be a solved problem in our lifetime. Think about that for a second, the biggest minds of a generation, literally billions of dollars of investment and it’s unlikely to be solved?
Search tech has lagged databases mainly due to language problems, yet we’ve seen a revolution in language processing over the last few years and it’s still speeding up! From a tech perspective, we see neural based hashes dropping the barrier for new search and database technology (us included!).
If you’re working on hash based neural networks and indexes, I’d love to hear your thoughts on what’s coming next!
About the Creator
Keep reading
More stories from writers in Futurism and other communities.
Review of 'Constellation'
I've read and seen many alternate reality stories. Some are caused by quantum entanglement -- the mega version of two subatomic particles colliding and then moving in opposite directions but still intimately and instantly connected -- and some just happen or are already there. I just reviewed a movie here on Vocal with that schema, and have written a few double realities stories and a novel with that premise myself. But none explore the existence and impact of that on families the way that Constellation does. Indeed, none do much of that at all in the at once deep and startling way that this new series on Apple TV+ does.
By Paul Levinson3 days ago in Futurism




Comments
There are no comments for this story
Be the first to respond and start the conversation.