
Natural Language Processing (NLP) modules :
#nlp #Ai #spacy #gensim


There are several modules or libraries commonly used in Natural Language Processing (NLP) that provide pre-built functions and tools for various NLP tasks. Some examples include:
NLTK (Natural Language Toolkit):

NLTK is a powerful Python library for working with human language data. It provides functions for tokenization, stemming, and part-of-speech tagging,
as well as tools for parsing and semantic reasoning.
The Natural Language Toolkit (NLTK) is a Python library for working with human language data. It provides a wide range of tools and resources for natural language processing tasks such as tokenization, stemming, and tagging, as well as more advanced tasks like parsing and semantic reasoning. NLTK also includes a variety of corpora and lexical resources, such as WordNet (a large lexical database of English) and the Brown Corpus (a large corpus of text in English).
NLTK is designed to be easy to use and understand, making it a popular choice for students and researchers in NLP, as well as for developers building NLP-enabled applications.
Here are a few examples of the types of tasks that can be performed using NLTK:
In addition to providing a wide range of NLP functionality, NLTK also includes a number of functionality for text processing and visualization such as wordclouds, frequency distributions, and collocations.
NLTK is a powerful toolkit that can be used to perform a wide range of natural language processing tasks, and it provides an easy-to-use interface for working with human language data in Python.
spaCy:
spaCy is a library for advanced natural language processing in Python. It is designed specifically for production use, and it is fast and efficient. It provides functions for tokenization, part-of-speech tagging, named entity recognition, and more.
spaCy is a popular open-source library for advanced natural language processing in Python. It is designed specifically for production use, providing fast and efficient performance for large amounts of text. spaCy is also designed to be easy to use, with a simple and consistent API.
One of the main features of spaCy is its ability to perform various NLP tasks, such as tokenization, part-of-speech (POS) tagging, named entity recognition (NER), dependency parsing and similarity detection, all using the same underlying model. spaCy also includes pre-trained models for several languages, making it easy to get started with common NLP tasks in those languages.
spaCy is a powerful and efficient library for natural language processing that is well-suited for production use. It provides a simple and consistent API for performing a wide range of NLP tasks, and it includes pre-trained models for several languages.
Gensim:
Gensim is an open-source Python library for natural language processing, specifically for topic modeling and document similarity analysis. It is designed to be efficient and scalable, making it suitable for working with large amounts of text data.
One of the main features of Gensim is its implementation of various topic modeling algorithms, such as Latent Semantic Analysis (LSA), Latent Dirichlet Allocation (LDA), and Hierarchical Dirichlet Process (HDP). These algorithms can be used to discover latent topics in a corpus of text, and to represent documents as a mixture of these topics.

Gensim also provides interfaces to other popular NLP libraries such as NLTK and spaCy and also provides a number of built-in utilities for working with text data, such as loading and saving corpora in various formats, and for filtering and transforming text data.
In summary, Gensim is a powerful and efficient library for topic modeling and document similarity analysis, it is designed to be efficient and scalable and it provides interfaces to other popular NLP libraries and utilities for working with text data, making it a useful tool for a wide range of natural language processing tasks.
OpenNLP :
OpenNLP, short for Open Natural Language Processing, is an open-source natural language processing library developed by the Apache Software Foundation. It provides a wide range of NLP functionality, including tokenization, part-of-speech tagging, named entity recognition, parsing, and coreference resolution.
OpenNLP is designed to be easy to use, efficient and scalable. It can be integrated with other machine learning libraries and frameworks to improve the performance of NLP tasks. OpenNLP also provides pre-trained models for several languages including English, Spanish, German, French, and Chinese.

One of the main advantages of OpenNLP is that it is open-source and free to use, this makes it accessible to a wide range of users, including researchers, developers, and companies. It is also designed to be easy to use and easy to integrate with other machine learning libraries and frameworks.
OpenNLP can be used through an API, which allows the user to access its functionality programmatically. The API is available in multiple languages including Java, Python, and C#.
In summary, OpenNLP is an open-source natural language processing library developed by the Apache Software Foundation, it provides a wide range of NLP functionality, including tokenization, part-of-speech tagging, named entity recognition, parsing, and coreference resolution. It's designed to be easy to use, efficient and scalable, it's free to use and it can be integrated with other machine learning libraries and frameworks to improve the performance of NLP tasks. OpenNLP can be used through an API that is available in multiple languages.
CoreNLP :
CoreNLP, short for Stanford CoreNLP, is a suite of natural language processing tools developed by the Natural Language Processing Group at Stanford University. It is written in Java and provides a wide range of NLP functionality, including tokenization, part-of-speech tagging, named entity recognition, parsing, and coreference resolution.
CoreNLP is widely used in the NLP research community and it's considered one of the most accurate and powerful NLP tools available. It has been used in many academic studies and research projects, and has also been integrated into a number of commercial products.

One of the main advantages of CoreNLP is that it provides a wide range of NLP functionality in one package, making it a useful tool for a wide range of natural language processing tasks. Another advantage is that it's based on machine learning, which makes it more accurate than other simple rule-based systems.
CoreNLP can be used through an API, which allows the user to access its functionality programmatically. The API is available in multiple languages including Java, Python, C#, and Perl.
In summary, CoreNLP is a powerful and widely used suite of natural language processing tools developed by Stanford University.
It provides a wide range of NLP functionality, including tokenization, part-of-speech tagging, named entity recognition, parsing, and coreference resolution, based on machine learning, it's considered one of the most accurate and powerful NLP tools available. It can be used through an API that is available in multiple languages.
Here are a few examples of the types of tasks that can be performed using in all above modules :
Tokenization:
Breaking text into individual words or tokens.
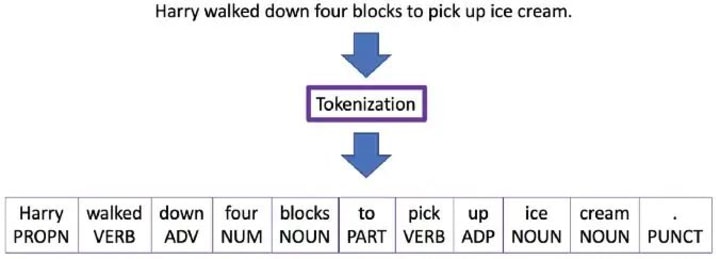
Tokenization is the process of breaking up a stream of text into individual words, phrases, symbols, or other meaningful elements, known as tokens. Tokens are the basic building blocks for most natural language processing tasks, such as text classification, language translation, and text generation.
Part-of-speech tagging:
Assigning grammatical information (such as noun, verb, adjective) to each token in a sentence.Part-of-Speech (POS) tagging is the process of marking up the words in a text as corresponding to a particular part of speech, based on both its definition and its context. POS tagging is a common pre-processing step for many natural language processing tasks, including text classification, parsing, and named entity recognition.

Named entity recognition:
Identifying and classifying named entities (such as people, organizations, locations) in a text.
Named Entity Recognition (NER) is the process of identifying and classifying named entities in a text into predefined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
It is a subtask of information extraction that seeks to locate and classify named entities in text into predefined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
Parsing:
Analyzing the grammatical structure of a sentence and identifying the syntactic relationships between words.
Parsing in NLP is the process of analyzing a sentence or text in order to understand its grammatical structure and relationships between words, phrases and clauses. It is a fundamental task in natural language processing, as it enables the computer to understand the meaning of a sentence and extract important information from it.
Sentence Detection:
Sentence detection, also known as sentence boundary detection or sentence segmentation, is the process of identifying the boundaries between sentences in a piece of text. It is an important step in natural language processing (NLP) tasks such as text summarization, text classification, and machine translation.
There are several methods for sentence detection, including rule-based approaches and machine learning-based approaches. Rule-based approaches use a set of pre-defined rules to identify sentence boundaries, such as looking for punctuation marks like periods and exclamation points. Machine learning-based approaches, on the other hand, use algorithms such as decision trees or recurrent neural networks to learn the patterns of sentence boundaries from a training dataset.

Sentence detection is a challenging task because it must take into account variations in punctuation, capitalization, and other factors that can affect the appearance of sentence boundaries. For example, a period may be used to indicate the end of a sentence, but it may also be used in an abbreviation or a numerical value. Sentence detection systems must be able to distinguish between these different uses of punctuation in order to accurately identify sentence boundaries.
Sentence detection is a process to identify the boundaries between sentences in a piece of text, it is an important step in Natural Language Processing (NLP) tasks such as text summarization, text classification, and machine translation, it can be done by rule-based approaches or machine learning-based approaches.
About the Creator
ARUNINFOBLOGS
A information content writer creating engaging and informative content that keeps readers up-to-date with the latest advancements in the field.
Most of i write about Technologies,Facts,Tips,Trends,educations,healthcare etc.,
Keep reading
More stories from ARUNINFOBLOGS and writers in Futurism and other communities.
Future manufacturing based on Artificial Intelligence
In manufacturing, AI can be used for predictive maintenance, supply chain optimisation, and process control. Yes, that is correct. In manufacturing, AI can be used for a variety of purposes to improve efficiency, reduce costs and increase productivity.
By ARUNINFOBLOGSabout a year ago in Futurism
Enhancing Product Quality Review through Automated Excursion Handling in Pharmaceutical Manufacturing
Effective excursion handling is vital in pharmaceutical manufacturing to maintain product quality and regulatory compliance. Integrating technological solutions into Product Quality Review (PQR) workflows offers a comprehensive approach to address deviations promptly and efficiently. By automating excursion handling processes within the PQR framework, pharmaceutical companies can ensure timely resolution of issues, enhance product quality, and streamline regulatory compliance.
By Prashant Upadhyay2 days ago in Futurism




Comments
There are no comments for this story
Be the first to respond and start the conversation.