
Architecture of Natural Language Processing (NLP)
#nlp #ai #ml #algorithms

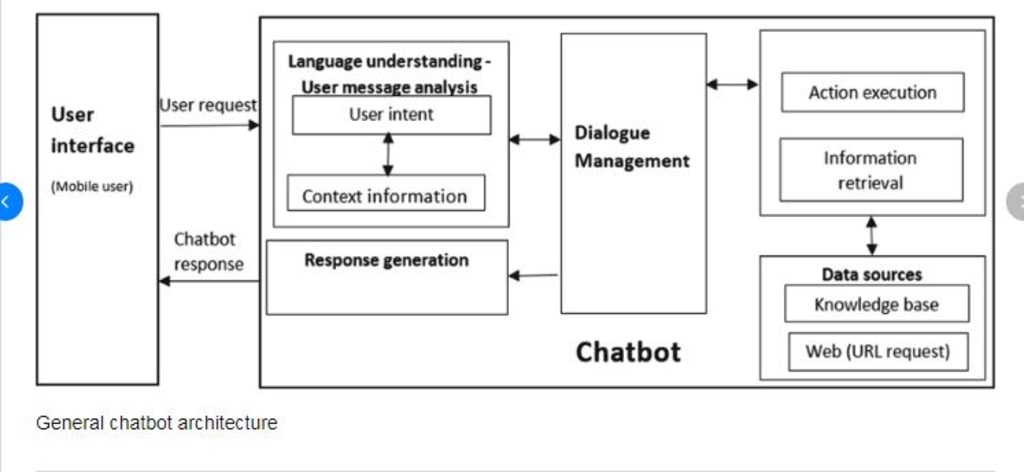
Architecture of Natural Language Processing (NLP) :
The architecture of Natural Language Processing (NLP) typically involves several steps or components, which can include:
Text Pre-processing :
Text pre-processing is the process of cleaning, structuring and normalizing text data before it is used for natural language processing tasks such as machine learning or text analysis. This typically involves steps such as removing special characters, lowercasing all text, removing stop words, stemming or lemmatizing words, and tokenizing the text into individual words or phrases. The goal of text pre-processing is to prepare the text data in a format that is easily understood and analyzed by machine learning models.
Sure, here are some examples of common text pre-processing steps:
Removing special characters:
This step involves removing any non-alphabetic characters from the text, such as punctuation marks or numbers. This is done to eliminate any noise in the data that could confuse the analysis.
Lowercasing:
This step involves converting all text to lowercase. This is done to ensure that words that are capitalized in one instance and lowercase in another are not treated as separate entities.
Removing stop words:
Stop words are common words that do not add much meaning to the text, such as "the," "and," "or," etc. These words are often removed to reduce the dimensionality of the data and focus on the more meaningful words.
Stemming/Lemmatization:
These techniques are used to reduce words to their base form, which can help group together different forms of a word that have the same meaning. For example, "running" and "ran" would both be reduced to "run."
Tokenization:
This step involves breaking up the text into individual words or phrases, called tokens. This is a crucial step for many natural language processing tasks, as it allows the model to analyze each word or phrase independently.
These are the common steps and there are other steps like removing numbers, removing HTML tags, replacing words/phrases with their synonyms, etc.
It's worth noting that the specific pre-processing steps required will depend on the task at hand and the nature of the text data. Not all steps are always necessary, and sometimes additional steps may be needed to properly structure the data.
Tokenization :
Tokenization is the process of breaking up a stream of text into individual words, phrases, symbols, or other meaningful elements, known as tokens. Tokens are the basic building blocks for most natural language processing tasks, such as text classification, language translation, and text generation.
There are several different ways to tokenize text, including:
Word Tokenization:
This is the most common form of tokenization, where the text is split into individual words. This can be done using white space or punctuation as delimiters.
Sentence Tokenization:
This method splits the text into individual sentences, allowing for the analysis of the structure and meaning of the text at the sentence level.
Character Tokenization:
This method breaks the text into individual characters, which can be useful for tasks such as language generation or text completion.
N-gram Tokenization:
This method splits the text into sequences of words, phrases or characters. For example, a bigram tokenization would produce tokens of two words.
RegEx Tokenization:
This method tokenizes the text based on a regular expression pattern. It can be used to tokenize the text in a specific format like email, phone number, etc.
Regardless of the specific method used, the goal of tokenization is to convert the raw text into a format that can be easily analyzed and processed by natural language processing models.
It's worth noting that tokenization is important for many NLP tasks, but some tasks like Sentiment Analysis, Named Entity Recognition, etc. can be performed on the un-tokenized text as well. The tokenization step also provides flexibility for the model to use different n-grams for its analysis.
Part-of-Speech Tagging :
Part-of-Speech (POS) tagging is the process of marking up the words in a text as corresponding to a particular part of speech, based on both its definition and its context. POS tagging is a common pre-processing step for many natural language processing tasks, including text classification, parsing, and named entity recognition.
Some common POS tags include:
Nouns:
words that represent a person, place, thing, or idea
Verbs:
words that indicate an action or state of being
Adjectives:
words that describe or modify nouns
Adverbs:
words that describe or modify verbs, adjectives, or other adverbs
Pronouns:
words that take the place of nouns
Prepositions:
words that indicate the relationship between a noun and other words in a sentence
Conjunctions:
words that connect words, phrases, or clauses
Interjections:
words that express strong emotion or surprise
There are various algorithms and tools to do POS tagging. Some of the most common techniques include:
Rule-based Tagging:
This approach uses a set of hand-written rules to assign POS tags to words based on their morphological features and context.
Statistical Tagging:
This approach uses machine learning algorithms to train a model on a large corpus of pre-tagged text, and then use this model to predict the POS tags of new text.
Hybrid Methods:
This approach combines the strengths of rule-based and statistical methods to improve the accuracy of POS tagging.
POS tagging is an important step for many natural language processing tasks because it provides the model with a deeper understanding of the structure and meaning of the text. This information can be used to identify the main subjects and objects in a sentence, determine the tense and mood of verbs, and identify idiomatic expressions. Additionally, it can be used to improve the results of other NLP tasks like parsing, text summarization, sentiment analysis, etc.
Named Entity Recognition :
Named Entity Recognition (NER) is the process of identifying and classifying named entities in a text into predefined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc. It is a subtask of information extraction that seeks to locate and classify named entities in text into predefined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
Named entities can be classified into several categories, including:
Person: names of people, including proper names, titles, and pronouns
Organization:
names of organizations, including companies, agencies, and institutions
Location:
names of geographical locations, including countries, regions, cities, and landmarks
Time:
expressions of time, including dates and times
Quantity:
expressions of quantity, including numerical values and units of measurement
Percentage:
expressions of percentage
Monetary:
expressions of monetary values, including currency and amounts
There are several methods for performing Named Entity Recognition, including:
Rule-based :
This approach uses a set of hand-written rules to identify named entities based on their morphological features and context.
Statistical :
This approach uses machine learning algorithms to train a model on a large corpus of pre-tagged text, and then use this model to predict the named entities in new text.
Hybrid :
This approach combines the strengths of rule-based and statistical methods to improve the accuracy of named entity recognition.
Named Entity Recognition is an important task in many natural language processing applications, such as information retrieval, text summarization, question answering and machine translation. It can be used to extract useful information from unstructured text, to improve the performance of other NLP tasks, and to create structured data from unstructured text. Additionally, it can be used in various industries such as finance, healthcare, e-commerce, and media to extract important entities and improve the decision-making process.
Parsing :
Parsing in NLP is the process of analyzing a sentence or text in order to understand its grammatical structure and relationships between words, phrases and clauses. It is a fundamental task in natural language processing, as it enables the computer to understand the meaning of a sentence and extract important information from it.
There are two main types of parsing:
Syntactic parsing:
This type of parsing focuses on analyzing the grammatical structure of a sentence, such as identifying the subject, verb, and object. It also looks at the relationships between words, such as clauses and phrases, in order to understand how the sentence is constructed.
Semantic parsing:
This type of parsing goes beyond the grammatical structure of a sentence and looks at the meaning of the words and how they relate to each other. It aims to extract the meaning of the sentence and identify the relationships between entities and events.
There are several methods to perform parsing, including:
Rule-based parsing:
This approach uses a set of hand-written rules to analyze the sentence structure and extract the meaning.
Statistical parsing:
This approach uses machine learning algorithms to train a model on a large corpus of pre-parsed text, and then use this model to parse new text.
Hybrid parsing:
This approach combines the strengths of rule-based and statistical methods to improve the accuracy of parsing.
Parsing is used in a wide range of natural language processing applications, such as text-to-speech systems, machine translation, information extraction, and question answering. It is also used in many industries such as finance, healthcare, e-commerce, and media to extract information and improve the decision-making process. Additionally, it can be used in natural language generation tasks to generate grammatically correct sentences.
Sentiment Analysis :
Sentiment Analysis, also known as Opinion Mining, is the process of using natural language processing and text analysis techniques to identify and extract subjective information from source materials. It aims to determine the attitude, opinions, and emotions of a speaker or writer with respect to some topic or the overall contextual polarity of a document.
There are several methods for performing Sentiment Analysis, including:
Rule-based:
This approach uses a set of hand-written rules to identify sentiment based on the presence of specific words or phrases in the text.
Statistical:
This approach uses machine learning algorithms to train a model on a large corpus of pre-labeled text, and then use this model to predict the sentiment of new text.
Deep learning:
This approach uses neural networks to process the text and identify sentiment.
Sentiment analysis is used in a wide range of applications, including social media monitoring, marketing, and customer service. In these applications, sentiment analysis can be used to extract insights from customer feedback, track brand reputation, and identify customer needs and preferences. Additionally, it can be used in various industries such as finance, healthcare, e-commerce, and media to extract public opinions and make strategic decisions.
It's worth mentioning that Sentiment Analysis is not a trivial task, there are many challenges to be tackled, such as irony, sarcasm, negations and idiomatic language, that can make the task of determining the sentiment of a text quite difficult, and the performance of models can be affected by these challenges.
Text Generation:
Text generation in natural language processing (NLP) refers to the process of using AI algorithms to generate natural language text that is similar to human-written text. This can be done by training a model on a large corpus of text, such as a dataset of books, articles, or social media posts, and then using the model to generate new text based on patterns it has learned from the training data.
There are several different types of text generation models that are used in NLP, including:
Markov Chain Models:
Markov Chain models are based on the idea that the probability of a word occurring in a text is dependent on the previous words in the text. These models can be used to generate new text by randomly selecting words based on the probabilities learned from the training data.
Recurrent Neural Networks (RNNs):
RNNs are a type of neural network that are designed to process sequential data, such as text. They can be used to generate new text by predicting the next word in a sentence based on the previous words in the sentence.
Generative Pre-trained Transformer (GPT) models:
GPT models are a type of transformer neural network that are pre-trained on a massive amount of text data and fine-tuned on a specific task, such as text generation.
Transformer-Decoder Models:
Transformer-Decoder models are a type of neural network architecture used for text generation. They consist of an encoder that processes the input text and a decoder that generates the output text.
One of the most popular and powerful models for text generation is GPT-3, which is a pre-trained transformer model developed by OpenAI. GPT-3 has been trained on a massive amount of text data and can generate text that is highly similar to human-written text.
Text generation can be used in a variety of applications, such as:
Content generation for websites or social media
Text completion to help users write emails, reports, or other documents
Summarization of long documents
Text generation in creative writing, poetry, and fiction
Dialogue generation for chatbots and virtual assistants
Machine Translation
However, it's important to note that text generation models can also produce text that is nonsensical or offensive, so it's important to be mindful of the potential ethical implications of using these models.
Text Summarization:
Text summarization in natural language processing (NLP) refers to the process of automatically generating a shorter version of a longer text document while preserving its most important information. The goal of text summarization is to reduce the length of a text while keeping the most important information, which can be useful in a variety of applications, such as content summarization for websites or social media, summarization of long documents, and summarization of news articles.
There are several different types of text summarization methods that are used in NLP, including:
Extractive Summarization:
Extractive summarization methods involve selecting the most important sentences or phrases from the original text and concatenating them to form a summary. These methods rely on techniques such as keyword extraction, sentence scoring, and clustering to identify the most important sentences.
Abstractive Summarization:
Abstractive summarization methods involve generating new text that is a summary of the original text. These methods rely on techniques such as natural language generation, text generation, and machine learning to generate a new summary.
Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA):
Both LSA and LDA are used as a method to extract the main topics from a given text and then generate a summary based on those topics.
One of the most popular and powerful models for text summarization is the transformer-based models such as BERT, GPT-2, GPT-3, etc. These models are pre-trained on a large corpus of text data and can be fine-tuned for text summarization tasks.
Text summarization can be used in a variety of applications, such as:
Content summarization for websites or social media
Summarization of long documents
Summarization of news articles
Summarization of scientific papers
Summarization of customer reviews
Summarization of emails
Machine Translation:
This module translates text from one language to another.
Machine Translation (MT) is a subfield of Natural Language Processing (NLP) that deals with automatically translating text from one language to another. The goal of MT is to produce translations that are as accurate and natural as possible, while also being able to handle the many complexities and nuances of human language.
There are several different approaches to MT, but the most commonly used are statistical machine translation (SMT) and neural machine translation (NMT).
Statistical Machine Translation (SMT) uses large parallel corpora of text in different languages to learn statistical models that can be used to translate text. The models are trained to identify patterns and relationships between words and phrases in the source language and their corresponding translations in the target language.
Neural Machine Translation (NMT) uses deep learning techniques to train a neural network to translate text. The neural network is trained on a large dataset of parallel text and learns to generate translations by encoding the source text into a fixed-length vector representation, and then decoding this representation into the target language. NMT has proven to be more accurate than SMT, especially for languages with complex grammar and sentence structures.
MT systems can be used in a variety of applications, such as machine-aided human translation, machine-aided localization, and automatic translation of web pages and social media posts. However, it's important to note that despite the recent progress in MT, the technology is not yet at the point where it can fully replace human translators, especially in cases where idiomatic expressions, cultural references, and professional terminology are involved.
However, it's important to note that text summarization, like text generation, also has its limitations and can produce summaries that are inaccurate, incomplete or biased. Therefore, it is important to evaluate and verify the generated summary before using it.
This step involves summarizing the text by extracting the most important information and condensing it into a shorter form.
These steps may vary depending on the specific task and application of NLP, and some steps may be skipped or added depending on the requirement.
About the Creator
ARUNINFOBLOGS
A information content writer creating engaging and informative content that keeps readers up-to-date with the latest advancements in the field.
Most of i write about Technologies,Facts,Tips,Trends,educations,healthcare etc.,
Keep reading
More stories from ARUNINFOBLOGS and writers in Education and other communities.
Photikodi was a currency of the Mughal era with the lowest value. 3 broken whips made one whip and 10 whips made one tail. Apart from this, in everyday Urdu language, "Phuti Koori" is also used idiomatically as a symbol of neediness, for example, I have not even a Phooti Koori left.
Photikodi was a currency of the Mughal era with the lowest value. 3 broken whips made one whip and 10 whips made one tail. Apart from this, in everyday Urdu language, "Phuti Koori" is also used idiomatically as a symbol of neediness, for example, I have not even a Phooti Koori left.
By Muhammad Tariq4 days ago in Education




Comments
There are no comments for this story
Be the first to respond and start the conversation.