
The Perfect Picture is Created Through AI
The inner-workings of Machine Learning models explained in layman's terms.


I'm a software engineer by profession and a novice photographer. I have used the term novice a little loosely here. Okay, I'll admit. I have no idea about photography. All I know is, when I click the button on my phone, the camera takes a picture. But I know how to analyze the photos I took. With Machine Learning getting traction over the past decade, my work involves designing the ML models and using them for various applications. Photo editing is one such example. Give me a photo of Kanye West, and I can make him smile. Give me your best picture, and I can transform it into a Van Gogh-like art. Imagine that. AI copying the styles of various artists. There are much more applications in the AI space, but since we're dealing with photos, let us look at some of the ground-breaking technologies in image transformation.
Terms Used
AI - Artificial Intelligence
ML - Machine Learning (AI and ML are used interchangeably)
Model - A model is a trained algorithm that can function based on learning patterns from the training data.
Neural Network - It is a set of algorithms meant to mimic the functions of the human brain in terms of recognizing patterns.
Style Transfer

Have you ever imagined what your photo would look like if it were painted by a famous artist? Now you don't have to, as Neural Style Transfer does exactly that. No, don't wake up Van Gogh from the dead. The ML model learns all the artworks of Van Gogh and applies the style unique to his paintings to your picture, thereby converting your photo into a Van Gogh-like painting.
Try it yourself : https://deepart.io/
What happens behind?

Inputs - Style image (Image of the artist) and Content image (Your photo)
Output - A single image that is a blend of the Style and Content images.
You feed the neural network with the inputs and calculate the loss function from it. The loss function is a measure to determine how much the Style and the Content images have blended. You repeat this process until you reach the optimal loss. Basically, you're applying the styles from the Style image such as the patterns, brush strokes, textures, etc to the Content image. The resulting output is a single image of your photo in the style of your favorite artist.
AI Created Imagery

DALL-E is an OpenAI initiative that converts text into images. The creators have named the model DALL-E, which is a portmanteau of Salvador Dali and WALL-E. Let's say you want to see an avocado in a suit watching tv for some weird reason. You give the exact text as input, and DALL-E produces images, with avocado in a suit watching tv. Interesting. Isn't it? Imagine what else the model can create. The possibilities are endless. And that's why DALL-E has not yet been released to the public. It is the most powerful model built yet, so the consequences of a public release are unknown. Below is the statement on the OpenAI website.
We recognize that work involving generative models has the potential for significant, broad societal impacts. In the future, we plan to analyze how models like DALL·E relate to societal issues like economic impact on certain work processes and professions, the potential for bias in the model.
Try it yourself : https://openai.com/blog/dall-e/
What happens behind?
DALL-E makes use of the Transformer architecture, a type of neural network trained with massive datasets. It makes use of the attention mechanism, which selectively concentrates only on the relevant data.
For example, given a photo of a bus with the driver and passengers, you are asked to locate the baby in it. Your attention will now be only on the baby, and the rest of the information in the photo is irrelevant. The attention mechanism in neural networks mimics the same concept.
Given a set of text and pixels, DALL-E uses the attention mechanism to focus on the specific parts of the text and pixels, thereby creating the output image.
Face Swap

Want to see how you look in the Iron Man suit? Or if you were one of the Na'vi people in The Avatar? Face Swap compares your face with the reference image you select and merges your face with it. The same concept can also be applied to age, smile, and other features of the face. You can change your facial characteristics as you wish. If you are worried about how your nose looks, you can edit it with the face swap algorithm. With this, you never have to worry about all the duck faces of your friends in your precious photos again. Enough with the duck faces already!
Try it yourself : https://reflect.tech/
What happens behind?
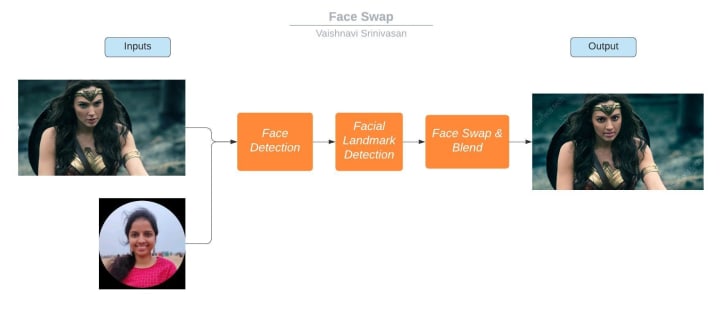
Inputs - Two photos
Output - Face swapped photo
You feed the inputs to the Face Detection network. It is a set of algorithms that detects the face and passes the information to the Facial Landmark Detection network. Facial Landmark Detection involves identifying the anchor points on the face such as eyes, nose, lips, eyebrows, etc. This information is then passed to the Face Swap & Blend network. It runs a set of algorithms to ensure that the anchor points are swapped and makes the final blend. Voila! Your face-swapped output photo is ready to share with the world.
References:
1. https://towardsdatascience.com/a-brief-introduction-to-neural-style-transfer-d05d0403901d
2. https://www.fritz.ai/style-transfer/
3. https://arxiv.org/abs/1508.06576
4. https://arxiv.org/pdf/2102.12092.pdf
----------------------
Author's Note:
This article is not a replacement for the technical papers, but it attempts to explain the concepts in layman's terms. Writing this involved some research into the latest trends in Machine Learning and a few late nights after the day job. I've shared above the articles I referred to be able to write this.
If you liked what you read, feel free to hit the heart or tip. I'm also a part of the Facebook group Vocal Creators Saloon. You can reach me there for any clarifications. Cheers!
About the Creator
vaisrinivasan
Writer of musings. Occasional traveller.
https://ko-fi.com/vaishnavi_scribbles
Keep reading
More stories from vaisrinivasan and writers in 01 and other communities.
In Conversation With Chiron
I was out on a Saturday. You know, spending some time in nature, cooling off the stress, with occasional Facebook checks. The Pine Forest is a famous tourist spot, but to my surprise, it was not crowded that day. Except for a few horses and a trainer nearby, it was practically empty. The trainer was a good-looking man. I wouldn't lie if I said I threw a couple of glances at him. I sat down on the grass, took a deep breath, immersing myself in "Percy Jackson and the Lightning Thief"; I don't know how much time had passed when I suddenly heard a voice say, "I trained him";
By vaisrinivasan3 years ago in Futurism
The Unsung Hero of Road Safety: Traffic Management Attenuators (TMA)
However, there is another unsung hero in the realm of traffic safety—the Traffic Management Attenuator (TMA). These unassuming devices play a critical role in protecting road workers and motorists from severe accidents and injuries, especially in construction zones and emergency response areas. In this blog, we explore what TMAs are, how they work, and why they're so vital for road safety.
By barleys Traffic2 days ago in 01
Understanding Dengue Tests: Types, Results, and What They Mean
Understanding Dengue Tests: Types, Results, and What They Mean Dengue fever is a mosquito-borne viral infection that affects millions of people worldwide each year. As there is no specific treatment for dengue, early detection and proper management are crucial for preventing severe complications. This article aims to provide a comprehensive understanding of dengue tests, including the types available, how they work, interpreting results, and what they signify.
By Amit Gupta6 days ago in 01



Comments
There are no comments for this story
Be the first to respond and start the conversation.