
Build a system to identify fake news articles!
Solving Real-World Problem Using Text Analytics and Classical Machine Learning Approach!

The epidemic spread of fake news is a side effect of the expansion of social networks to circulate news, in contrast to traditional mass media such as newspapers, magazines, radio, and television. Human inefficiency to distinguish between true and false facts exposes fake news as a threat to logical truth, democracy, journalism, and credibility in government institutions.
The veracity of information is an essential part of its integrity. The combat against fake news makes indissoluble the integrity and veracity checking of social networks’ information and data consumption in the application layer. The disclosure of fake content implies a waste of processing and network resources. Further, it consists of a serious threat to the information integrity and credibility of the provided service. Hence, the sharing of untrue information concerns the Quality of Trust (QoT) applied to the news dissemination, referring to how much a user trusts the content of a particular source.

In this post, we survey methods for preprocessing data in natural language, vectorization, dimensionality reduction, machine learning, and quality assessment of information retrieval. We also contextualize the identification of fake news.
Business Problem
To develop a machine learning program to identify when an article might be fake news.
User Guide
The Colab Notebooks are available for this real-world use case at my GitHub repository!
Understanding Data
You can download the dataset for the use case from Kaggle.
What is fake news? — The fake news term originally refers to false and often sensationalist information disseminated under the guise of relevant news. However, this term’s use has evolved and is now considered synonymous with the spread of false information on social media. It is noteworthy that, according to Google Trends, the “fake news” term reached significant popularity in 2017.
Fake news is defined as news that is intentionally and demonstrably false, or as any information presented as news that is factually incorrect and designed to mislead the news consumer into believing it to be true.
Data Overview
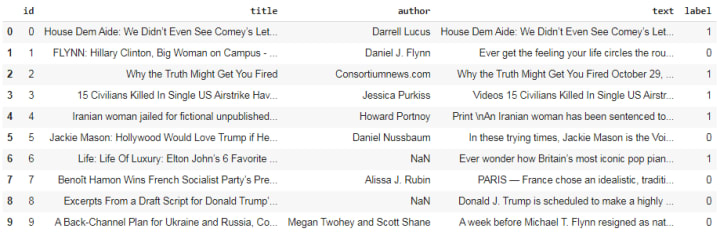
Data will be in a file train.csv. There are a total 20,800 number of observations or rows. It contains 5 columns: id(unique id for a news article), title(the title of a news article), author(author of the news article), text(the text of the article; could be incomplete), label(a label that marks the article as potentially unreliable) denoted by 1(unreliable or fake) or 0(reliable).
Type of ML Problem
It is a binary classification problem, for a given news article we need to predict if that is reliable or not.
Basic Exploratory Data Analysis
What is the total number of observations for training? — — 20,800.
Are there any missing values in the data?
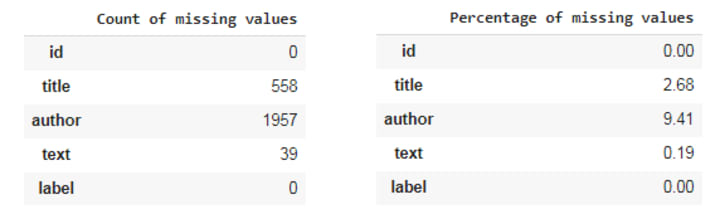
- The percentage of missing values is lesser hence we can drop those many observations.
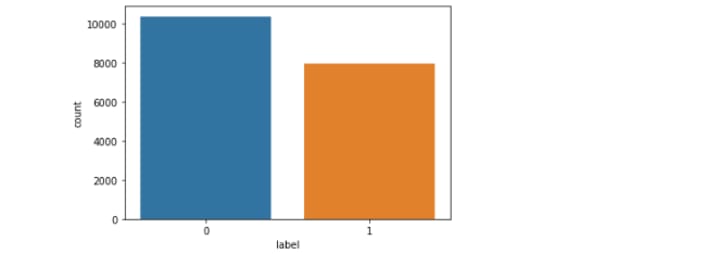
What is the distribution of class labels?
The number of unreliable articles(fake or 1) is 7924 and the number of reliable articles(0) is 10361, data don’t follow an imbalanced situation but almost 43% of the articles are FAKE! 😥
Which are the common authors of fake news articles?

Which are the common authors of reliable news articles?

Data Pre-processing
Why do we need to convert text data to numeric data?
- Computers only understand numbers.
- Once we convert our text into a vector, we can leverage the beauty of Linear Algebra.
Before we proceed, let’s understand two terms that will be used frequently in this post.
- Document- It is nothing but a file that has text data in it. In terms of a dataset, each record or data point can be considered as a document.
- Corpus- Set of documents is known as a corpus. In terms of a dataset, entire data points or the whole dataset can be considered a corpus.
Now we are good to go !!
The first step in text preprocessing is to remove special characters, stemming, and remove stop-words from ‘title’ feature. If you want to understand how to perform the above steps on text preprocessing then checkout Colab Notebooks. I have explained the steps using an example!
Note: I have considered only ‘title’ and ‘label’ features for pre-processing and model building. You can include other features also. I have tried keeping ‘text’ but performance metrics are not promisible!
After performing the above pre-processing steps, we need to convert the data to numbers. To do this, we will use a simple Bag of Words (BoW) approach.
Features Extraction using Bag of Words
A bag-of-words is a representation of text that describes the occurrence of words within a document. It involves two things:
- A vocabulary of known words.
- A measure of the presence of known words.
It is called a “bag” of words, because any information about the order or structure of words in the document is discarded. The model is only concerned with whether known words occur in the document, not where in the document.
A very common feature extraction procedures for sentences and documents is the bag-of-words approac. In this approach, we look at the histogram of the words within the text, i.e. considering each word count as a feature.
Let us understand from the following example:
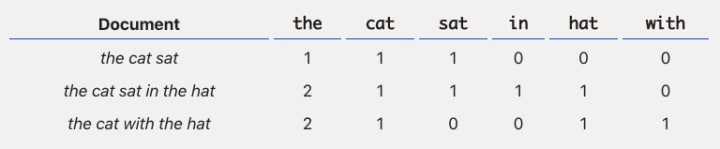
Here, the, cat, sat, in, hat, with are the 6 features for 3 documents and entries are the frequencies of those features. Very Simple. Isn’t it?
We will get 5000 features from the BoW.

Train-Test Split
Here, we will split our data into train-validation(test) in the ratio of 75:25. The number of data points in train data: 21141 and the number of data points in validation data: 7048.
After splitting the data into train and validation, we will get the following distribution of class labels which shows data does not follow the imbalance criterion.

Random Baseline Model
A baseline prediction algorithm provides a set of predictions that you can evaluate as you would any predictions for your problems, such as classification accuracy or loss. The random prediction algorithm predicts a random outcome as observed in the training data. It means that the random model predicts labels 0 or 1 randomly. The scores from these algorithms provide the required point of comparison when evaluating all other machine learning algorithms on your problem…
The accuracy of validation data using the Random Model is 50%. A lot of scopes to improve accuracy!
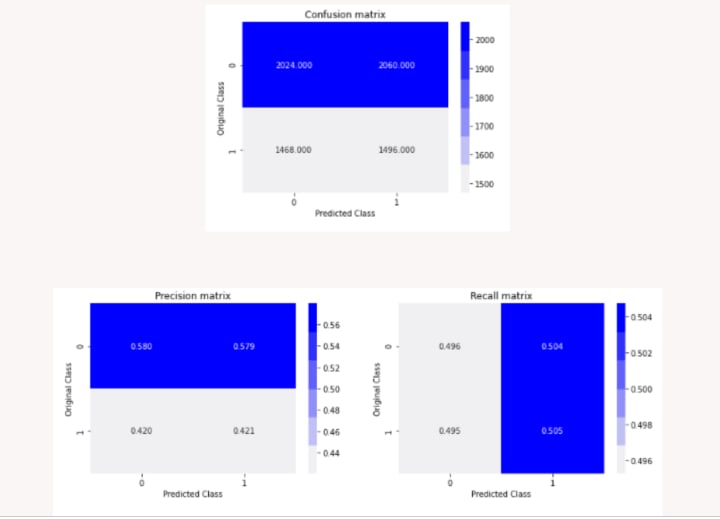
Multinomial Naive Bayes Classifier
Multinomial Naive Bayes algorithm is a probabilistic learning method that is mostly used in Natural Language Processing (NLP). The algorithm is based on the Bayes theorem and predicts the tag of a text such as a piece of email or newspaper article. It calculates the probability of each tag for a given sample and then gives the tag with the highest probability as output.
Naive Bayes classifier is a collection of many algorithms where all the algorithms share one common principle, and that is each feature being classified is not related to any other feature. The presence or absence of a feature does not affect the presence or absence of the other feature.
The accuracy on Train Data using MNB Model is 92%
The accuracy on Validation Data using MNB Model is 90%
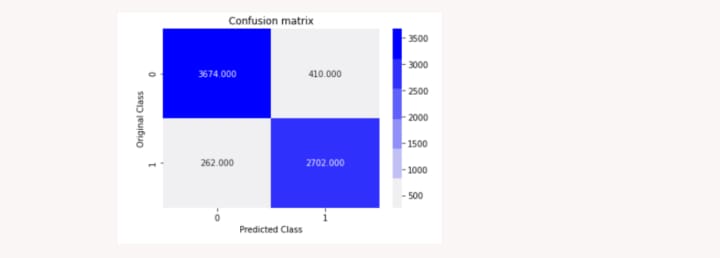
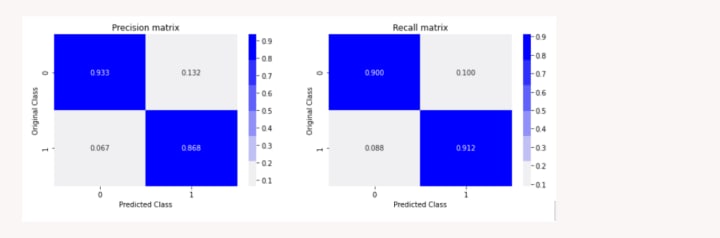
Passive Aggressive Classifier
Passive-Aggressive algorithms are generally used for large-scale learning. It is one of the few online-learning algorithms. In online ML algorithms, the input data comes in sequential order and the ML model is updated step-by-step. This is very useful in situations where there is a huge amount of data and it is computationally infeasible to train the data because of the sheer size of the data. We can simply say that an online-learning algorithm will get a training example, update the classifier, and then throw away the example. A good example is to detect fake news on Twitter, where new data is being added every second.
How does this algorithm work?
In simple terms:
- Passive: For correct prediction, keep the model and do not make any changes.
- Aggressive: For incorrect prediction, make changes to the model may be some change to the model that can correct it.
To learn more about the mathematics behind this algorithm, I recommend watching this excellent video on the algorithm’s working by Dr. Victor Lavrenko.
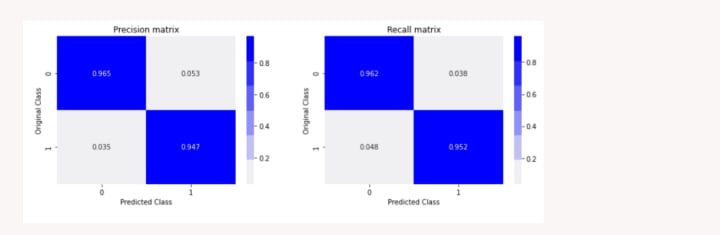
The accuracy on Train Data using PassiveAgressive Model is 100%
The accuracy on Validation Data using PassiveAgressive Model is 96%
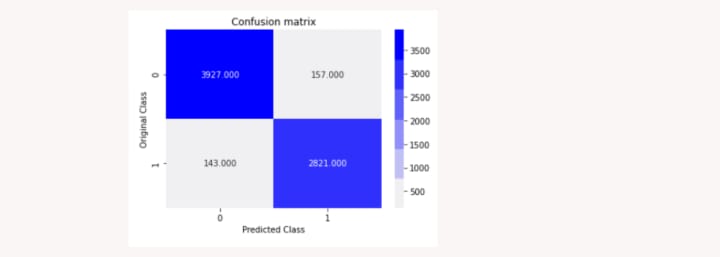
Thanks for reading ❤
References
- A Gentle Introduction to the Bag-of-Words Model by — Jason Brownlee
Resources
- Kaggle Competition — https://www.kaggle.com/c/fake-news/data.
---------------------------------------------------------------------------------------
Happy Learning! 😊
About the Creator
Keep reading
More stories from Priyanka Dandale and writers in 01 and other communities.
Review of the Best 8 Photo Touch-Up Tools in 2024
Photo touch-up, the process of enhancing and refining images, is a valuable skill that can take your photography to the next level. From minor adjustments like brightening a photo to more elaborate edits like smoothing skin or removing unwanted elements, photo editing software and apps offer a wide range of tools to enhance digital images. This article will explore the different types of apps and software for photo touch-ups, understanding the basics and advanced techniques for professional results.
By Chloe Huang5 days ago in 01




Comments
There are no comments for this story
Be the first to respond and start the conversation.