
5 Things to Know About Service Mesh Performance
Know this before you start with a Service Mesh

Service Mesh architectural patterns are bringing in evolutionary change in microservice architectural patterns, no doubt anymore. Cloud native deployments across industries are in various stages of adopting service mesh — evaluating, designing, integrating, deploying and some in production. Many of the highly impactful advantages of service mesh have been very vividly described across internet — load balancing, circuit breaking, health checks, security offloads, customized network management and so on. Figure 1 (source) provides a view on complexity in a service mesh.
1. What are you measuring?
Service mesh architectures deploy a sidecar proxies along with every microservice based application.
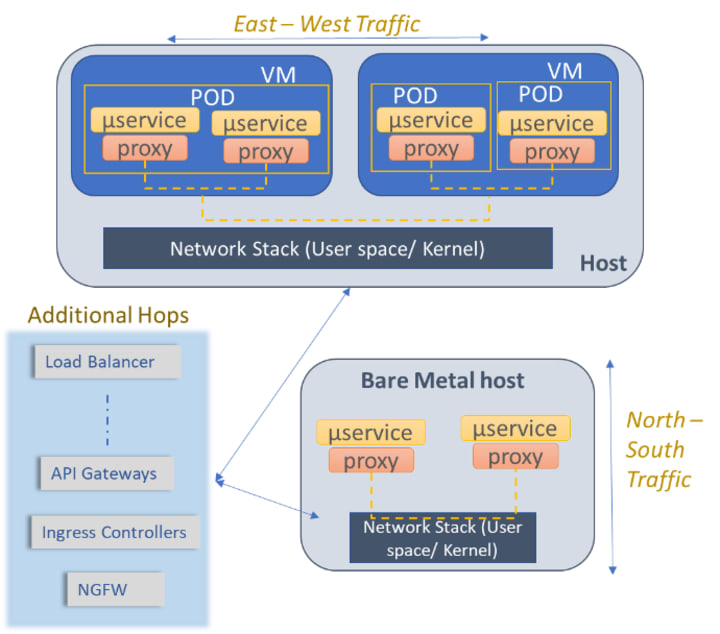
These are few communication patterns that usually occur within a Kubernetes cluster:
- Pod to pod communication
- Pod to service communication
- service to service communication
- Ingress controller to pod and vice-versa
- Load balancer to pod and vice-versa
- Pod to Egress controller
- Application gateway to services
- Traffic split, rate limiting
- Metrics, tracing, logging between the components
- TLS termination across any of the above endpoints, etc.
Its very critical to understand what communication patterns between these deployment elements to truly understand the performance. There can be any number of hops between two endpoints being measured for performance which directly correlate to negative impact on performance
2. What is the infrastructure?
In a production environment these microservices with sidecar proxies can be deployed:
- Across a single Kubernetes pod or
- Across multiple pods or
- Across multiple VMs within the same node or
- Across multiple nodes or
- As baremetal applications and so on
- Utilizing kernel of user mode networking stack
- Utilizing hardware acceleration such as SmartNICs or DPUs or IPUs
- Hardware power management
- Across NUMA nodes within the same node and so on
All of the above can have detrimental effect on microservice performance using sidecars. Without understanding these, a generic statement that microservice A to microservice B has 1000 Transactions Per Second (TPS) doesn’t provide full picture nor provide reproducible results.
3. How are you measuring?
The primary goal of any benchmarking should be consistent and repeatable results. Test methodology of ensuring a stable infrastructure and a load generator that can generate consistent load across multiple test cycles are key.
Standards such as RFC 2544 provide a guideline on how to measure throughput, latency, jitter, etc. between two endpoints and establish set of steps on how the load generator should scale the load across various situations. It is well known that changing load generator can change the performance results. It is imperative that measurements should be conducted using the same tool and same methodology.
Example of different throughput and latency within the same test environment:
Using the same environment but varying the tools used — Nighthawk vs. wrk2 vs. Fortio, there was a variation of up to 200 times! Go figure! Figure 3 (source) provides you the difference.

4. Scale of Benchmarking
Many assume studying performance would just be instantiate 2 end points, run the load between them capture results. In reality that’s just the beginning. Production environments requires massive scale of communications & interactions between multiple endpoints. Benchmarking should be done to reflect production workloads, traffic patterns, end point distribution, infrastructure tuning, etc., in order to provide a realistic impact of service mesh on application performance.

To up the notch a bit, to understand end to end impact of service mesh on performance, benchmarking should be considered across clusters, deploy end points such as application gateways, load balancers, etc., that heavily impact the performance and simulate the load that is close to realistic traffic request patterns (Figure 4). Consider these across private and public cloud type deployments.
5. Tuning across service mesh layers
The appealing aspect of a service mesh that pushes away the complexity of microservice networking away from application developers also adds in the fact that service mesh can be a black box to many. Vanilla deployments of a service mesh can be detrimental to overall end goal and bring out the worst across multiple aspects — deployment complexity, user experience, scaling, production performance, etc.
Hence a dedicated team is necessary to fine tune service mesh across control plane, management plane and data plane of a service mesh. Aspects such as TLS settings in and out a cluster, service to service communication requirements, bootstrapping configuration, latency tuning, infrastructure configuration, etc., need to be well understood before arriving at a stable set of benchmarks. Figure 5 (source) provides best practices from Envoy community.

What Next?
Regardless of whatever service mesh you choose — Istio, Kuma, Linkerd, etc., understand the overarching implications of its performance in your environment. There is a lot of ongoing work in the CNCF project — service mesh performance, that is addressing these challenges..

Figure 6 provides Service Mesh Performance Tooling using Meshery (source)
Personally, its been a real good experience with a team of technical experts dedicated to service mesh enabling. As indicated in SMP site, Service Mesh Performance (SMP) project is looking at:
- Establish a benchmarking specification defining terminology, KPIs, metrics of interest, etc.
- Provide an apples-to-apples performance comparisons of service mesh deployments.
- A universal performance index to gauge a service mesh’s efficiency against deployments in other organizations’ environments.
- Environment and infrastructure details
- Number and size of nodes
- Service mesh and its configuration
- Workload / application details
- Statistical analysis to characterize performance
In summary, there is still lot of work to be done before service meshes become mainstream. This is a real good moment in history to work on service meshes.
About the Creator
Enjoyed the story? Support the Creator.
Subscribe for free to receive all their stories in your feed. You could also pledge your support or give them a one-off tip, letting them know you appreciate their work.
The Complete Guide to Developing a Mobile App for Milk Delivery
In the fast-paced world of dairy business, having a mobile app for milk delivery can be a game-changer. With the increasing demand for doorstep milk delivery, leveraging technology to streamline operations and enhance customer satisfaction is essential. According to recent statistics, the global dairy market is projected to reach $587 billion by 2024, highlighting the immense potential for growth in this sector. This guide will walk you through the key steps and considerations in developing a mobile app for milk delivery, ensuring you can tap into this lucrative market effectively.
By Ella Butler2 days ago in 01
Second Tuesday of November
No one knew how the event really started. Between a few beverages at the bar, maybe? Notes passed carefully on the street? Or, perhaps a secret meetup at early hours of the day? Whatever the root source was, we were here now on the second Tuesday of November. Nervous, but also absorbed by the allure.
By Elizabeth Petit4 days ago in Fiction



Comments
There are no comments for this story
Be the first to respond and start the conversation.