
4 Ways to Avoid Website Crawlability Issues
Crawlability issues could lead to certain parts of your website being effectively off-limits to the search engines in error, preventing these pages from being indexed, appearing in the SERPs, or attracting any organic traffic as a result. Here are four ways to avoid these issues.

Crawlability relates to how easily (and thoroughly) a search engine’s crawler, often referred to as a spider, can access all of your site’s content.
Crawlability issues could lead to certain parts of your website being effectively off-limits to the search engines in error, preventing these pages from being indexed, appearing in the SERPs, or attracting any organic traffic as a result.
The fact is - any time, money, and effort you invest into creating new content for your site will ultimately be wasted if it proves to be inaccessible to the search engines crawlers.
Don't worry though; this article covers the fundamental things that you, or whoever is performing SEO services on your behalf, should look at to avoid the bulk of crawlability-related issues.
Let’s get stuck in.
1. Avoid Incorrectly Using the Meta Robots (‘Noindex’) Tag:
The ‘noindex’ option of the meta robots tag is useful in situations where you don’t want a particular web page to appear in the SERPs.
This could be for employee-only pages, or for landing pages holding special offers that only a select group of people should have access to, for example.
A web page that is omitted from the search results via the ‘noindex’ tag will have the following code in the <head> section of its HTML:
<meta name=“robots” content=“noindex”>
For example:
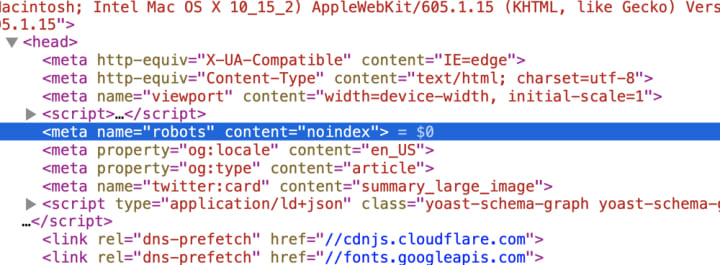
You need to be careful with the ‘noindex’ option of this tag on your website.
Regardless of how many pages link to a non-indexed page (either internally from your site or externally from another), how good the content is, or how many keywords the article contains, it will be omitted from the search results.
Clearly, this will be an issue if you want the page in question to rank.
You should regularly check to make sure there aren’t any pages on your site which are incorrectly set to ‘noindex’.
2. Prevent Robots.txt issues
The robots.txt file is a file which contains information relevant to the search engine crawlers that are sent out to crawl and index a website.
It can be used to allow or disallow access to specific files or folders.
Unlike the ‘noindex’ tag, which is applied to individual web pages, the robots.txt file’s code can be used to disallow access to entire files or folders at once.
This makes it incredibly useful and efficient, especially if you have huge quantities of pages that you don’t want appearing in the SERPs.
The robots.txt is arguably of more benefit on larger sites, as contrary to what most people think, there’s an argument to be made for preventing access to certain areas of your site to boost SEO.
You see, Google allocates a crawl budget to each website, with this budget dictating how many pages will be indexed on a website each time it is crawled.
On larger sites with thousands of posts, for example, denying access to certain files or folders that contain older content will allow the crawl budget to be distributed across newer areas of the website to ensure changes are indexed more quickly.
This can be incredibly useful from an SEO perspective.
It isn’t always plain sailing setting up the robots.txt file, however.
For example, if you accidentally prevent access to key files or folders, you run the risk of damaging your rankings given that certain pages may not be crawled or indexed properly.
Our advice?
Steer clear of a robots.txt file unless there’s a solid reason to use one.
Google has confirmed that you don’t need one anyway and that a website without a robots.txt can be crawled and indexed normally.
The bottom line?
If you do decide your site needs a robots.txt file, or you already have one in place, review it carefully to make sure it isn’t preventing access to key files and folders.
3. Don't Forget to Add a Sitemap
Back in the day, sitemaps were created in HTML, and they featured a list of links to each of a website’s pages to help visitors navigate around the site.
Nowadays, sitemaps are more commonly created in XML, and they’re usually added to help the search engines, not human visitors.
You won’t experience any direct ranking improvements from having a sitemap, but they can lead to indirect improvements thanks to helping the search engines crawl and index your website more fully.
As new content gets added to a website, for example, an up-to-date sitemap helps bring this to the attention of the search engines’ crawlers, making sure it gets added to the index more quickly than if the crawler was relying on finding the content through following followable links alone.
You should always have a functioning sitemap on your site to boost SEO.
4. Avoid Pages With Zero Inbound Links
Often referred to as orphan pages, these pages are effectively isolated and cut off because they have no ‘parent’ pages linking to them.
Orphan pages are a huge SEO issue because they nearly always end up not getting indexed, meaning they won’t appear in the SERPs.
You can’t just rely on these pages being listed in your site’s XML sitemap either.
There are two main issues from an SEO perspective.
Firstly, they don’t receive any of authority benefits or transfer of ‘link juice’ that usually occurs when one page links to another internally.
Secondly, it doesn’t do Google’s evaluation of what your site is about any favours as internal links are used to help search engines understand the context of a page’s content, and where it fits into a website as a whole.
The bottom line here?
If you absolutely, categorically want a page to be indexed and included in the SERPs, make sure it is linked to from other web pages on your site.
Spend time getting the internal linking structure on your site right.
Here’s an example:

One of the quickest and easiest ways to add internal links is via breadcrumbs (check out an example of breadcrumbs on this site: ToolCrowd - DEWALT DWS779 Review).
Conclusion
We hope you found this article both interesting and useful.
The key takeaway here is that you can’t expect your webpages and content to rank if it cannot be crawled and indexed fully.
There’s no point reinventing the wheel here, so feel free to steal this strategy to massively improve the effectiveness of your SEO and to boost your site’s standing with Google.
If you do require any assistance with your site’s SEO, the experts at BOOM Marketing Agency are always here to help.
***
Jonathan is a Senior Growth Strategist at BOOM SEO Agency in Belfast. When he isn’t exploding traffic to his clients’ sites, Jonathan can usually be found teaching SEO strategies, reading the latest business book, or planning his next snowboarding trip.
About the Creator
Keep reading
More stories from writers in 01 and other communities.
Boosting Online Sales with SEO Strategies for E-Commerce
In today's competitive e-commerce landscape, mastering SEO isn't just a choice; it's a prerequisite for success. Alongside top-notch products and services, standing out amidst countless online merchants is crucial.
By Prisha Shahabout 17 hours ago in 01




Comments (1)
Ensuring that your website is crawlable is essential to attract organic traffic from search engines. Crawlability is related to how easily and thoroughly a search engine's crawler can access all of your site's content. This article provides four fundamental things that you should consider to avoid crawlability-related issues. Firstly, you should avoid incorrectly using the meta robots tag, as pages will be omitted from the search results. Secondly, be cautious when using robots.txt file to allow or disallow access to specific files or folders. If you use this file, ensure that it is not preventing access to key files and folders. Thirdly, don't forget to add a sitemap on your site to boost SEO. Lastly, avoid pages with zero inbound links or orphan pages, as they nearly always end up not getting indexed, meaning they won’t appear in the SERPs. Overall, following these fundamental tips will help you avoid crawlability issues and improve your website's ranking on search engines.